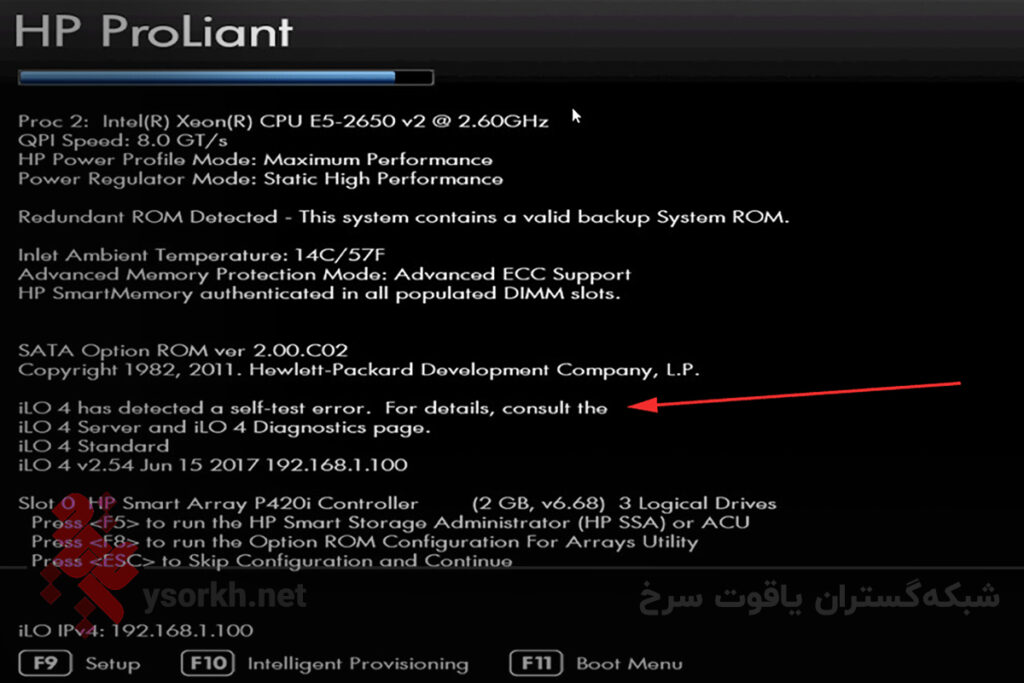
خطای “Self-Test Error” در هارد اچ پی به خطا هایی که وقتی هارد از خودش تست میگیرد اشاره دارد. وقتی سرور اچ پی را روشن میکنید، هارد دیسک ها نیز روشن میشوند و در اولین قدم هر هارد یک تست از خودش میگیرد، که اگر مشکلی وجود داشته باشد در مرحله POST ان را نشان میدهد، اگر در قسمت Intelligent نیز تست بگیرید هنگام تست خطای “Self-Test Error” نمایش داده میشود که احتمالاً به مشکلات سختافزاری در هارد دیسک اشاره دارد.
البته ممکن است این خطا علت های زیر را نیز داشته باشد.
- خرابی فیزیکی در سطح هارد دیسک: مشکلی در ساختار فیزیکی هارد دیسک بوجود آمده است که باعث میشود هارد نتوانداین مرحله را پاس کند و خطا را نشان میدهد.
- مشکل فیزیکی کنترلر هارد دیسک: کنترلر هارد دیسک مسئول مدیریت عملیات هارد دیسک است و اگر کنترلر خراب شود، self-test نمیتواند به درستی اجرا شود و خطا را نمایش میدهد.
- خرابی در بخشهای مکانیکی هارد دیسک: ممکن است بخشهای مکانیکی هارد دیسک مانند موتورها، سیستم حرکتی و غیره دچار خرابی شده باشند که باعث خطا در Self Test میشود.
در صورت بروز این خطا توصیه میشود هارد مورد نظر را با هارد سالم و نو تعویض نمایید البته باید دقت داشته باشید که چه نوع ریدی روی هاردها دارید و حتما از اطلاعاتتان بکاپ داشته باشید
آیا خطای “Self-Test Error” میتواند علت های نرمافزاری نیز داشته باشد؟
بله، خطای “Self-Test Error” در هارد اچ پی ممکن است به دلیل مشکلات نرمافزاری نیز رخ دهد. در ادامه علت های رایج را برایتان آورده ایم.
- مشکل درایور: درایورهای ناقص یا قدیمی بر روی سیستم باعث بروز خطاهای نرمافزاری در هارد دیسک میشود که در نتیجه خطای “Self-Test Error” را به دنبال دارد.
- نرمافزارهای ناسازگار و مخرب: برخی نرمافزاها میتواند باعث بروز خطا در عملکرد هارد دیسک شود و خطای “Self-Test Error” نمایش داده شود.
- مشکلات سیستم عامل: برخی مشکلات سیستم عامل نیز ممکن است توسط هارد دیسک تشخیص داده نشوند منجر به نشان دادن خطای “Self-Test Error” میشود.
اگر با خطای “Self-Test Error” در هارد اچ پی مواجع شدید میتوانید ابتدا به روزرسانی درایورها و نرمافزارها را انجام دهید. همچنین یک تست از عملکرد هارد بگیرید تا مطمئن شوید که مشکل از کجاست در صورت حل نشدن مشکل بهتر از یک مرکز و یا تکنسین متخصص کمک بگیرید.
خطای Self-Test Error در هارد اچ پی چیست؟
در زیرساختهای سازمانی و دیتاسنترها، عملکرد صحیح و پایدار هارد دیسک سرورها نقش حیاتی در تضمین تداوم خدمات، حفظ اطلاعات و جلوگیری از خرابیهای پرهزینه دارد. در میان برندهای معتبر بازار، سرورهای HPE به دلیل کیفیت ساخت، قابلیت اطمینان بالا و امکانات مدیریتی پیشرفته، جایگاه ویژهای در میان متخصصان آیتی دارند. یکی از مهمترین اجزای این سرورها، زیرسیستم ذخیرهسازی یا همان هارد دیسکها هستند که وظیفه نگهداری دادهها و پردازشهای روزمره را بر عهده دارند.
با توجه به ماهیت مکانیکی بسیاری از هاردهای مورد استفاده در سرورها و حساسیت آنها نسبت به دما، لرزش، نوسانات برق یا فرسودگی، پایش مداوم سلامت آنها برای جلوگیری از بروز اختلال الزامی است. شرکت HP برای افزایش قابلیت اطمینان و مدیریت بهتر این موضوع، سیستمهای مانیتورینگ هوشمند متعددی را در سرورهای خود تعبیه کرده است؛ یکی از مهمترین این قابلیتها، Self-Test یا آزمایش خودکار سلامت دیسک میباشد.
Self-Test نوعی فرآیند خودکار یا دستی است که با استفاده از فناوری S.M.A.R.T (Self-Monitoring, Analysis and Reporting Technology) در هارد دیسکها، امکان بررسی سلامت فیزیکی و عملکردی دیسک را بدون نیاز به جدا کردن آن از سرور فراهم میسازد. این تست در شناسایی اولیه مشکلاتی مانند سکتورهای خراب (Bad Sectors)، کندی در زمان پاسخدهی یا بروز خطاهای سختافزاری نقش بسیار مهمی دارد و میتواند هشدارهای پیشگیرانهای را در اختیار مدیران سیستم قرار دهد.
در صورتی که Self-Test Error گزارش شود، به این معناست که هارد در یکی از مراحل تست خودکار با خطا مواجه شده است؛ موضوعی که نباید نادیده گرفته شود، چراکه میتواند نشانهای از آغاز خرابیهای سختافزاری باشد و در صورت عدم پیگیری، منجر به از دست رفتن دادهها یا توقف عملکرد سرور شود.
در این مقاله، به بررسی دقیق مفهوم Self-Test در هاردهای سرورهای HP، علت بروز خطای Self-Test Error، روشهای تحلیل و راهکارهای رفع آن خواهیم پرداخت. همچنین نقش حیاتی پشتیبانی تخصصی و خدمات گارانتی شرکت شبکه گستران یاقوت سرخ را در مدیریت اینگونه خطاها معرفی خواهیم کرد تا راهنمایی جامع و کاربردی در اختیار کاربران حرفهای قرار گیرد.

HPE HDD Testing
Self-Test چیست؟
در دنیای تجهیزات ذخیرهسازی سازمانی، پایش پیوسته سلامت سختافزار امری حیاتی برای پیشگیری از خرابیهای پیشبینینشده و کاهش زمانهای ازکارافتادگی (Downtime) محسوب میشود. یکی از ابزارهای اصلی برای انجام این پایش در هارد دیسکهای سرورهای HPE، قابلیت Self-Test است که با استفاده از فناوری استاندارد S.M.A.R.T پیادهسازی میشود.
معرفی S.M.A.R.T Self-Test
فناوری S.M.A.R.T یا Self-Monitoring, Analysis and Reporting Technology، یک استاندارد صنعتی است که در انواع دیسکهای سخت (HDD) و درایوهای حالتجامد (SSD) مورد استفاده قرار میگیرد. هدف اصلی این فناوری، نظارت دائمی بر وضعیت داخلی دیسک و شناسایی زودهنگام خطاهای احتمالی است تا قبل از وقوع خرابیهای بحرانی، امکان انجام اقدامات پیشگیرانه فراهم شود.
یکی از زیرمجموعههای کلیدی این فناوری، S.M.A.R.T Self-Test است؛ فرآیندی خودکار یا دستی که در آن، هارد دیسک اقدام به بررسی وضعیت اجزای مختلف خود مانند:
-
هد خواندن و نوشتن
-
سطح دیسک (Platter)
-
جدول نگاشت سکتورها
-
حافظه کش
-
سرعت پاسخدهی و خطاهای انتقال داده
مینماید و در صورت مشاهده هرگونه ناسازگاری یا عملکرد غیرطبیعی، نتایج آن در قالب وضعیت Self-Test گزارش میشود. این اطلاعات میتواند از طریق نرمافزارهای مدیریتی مانند HPE Smart Storage Administrator (SSA)، HPE Insight Diagnostics یا لاگهای iLO (Integrated Lights-Out) مشاهده و تحلیل شود.

HPE HDD Self test
انواع Self-Test در هارد سرورها
فناوری S.M.A.R.T انواع مختلفی از تستها را برای بررسی سلامت دیسک ارائه میدهد که هر یک سطح متفاوتی از بررسی را انجام میدهند. در ادامه به معرفی اصلیترین آنها پرداختهایم:
1. Short Self-Test
-
مدت زمان تقریبی: کمتر از 2 دقیقه
-
هدف: بررسی سریع اجزای حیاتی دیسک
-
کاربرد: تشخیص فوری وجود مشکل بدون توقف طولانی سیستم
-
جزئیات بررسی: این تست به بررسی حافظه کش، موتور چرخان، عملکرد پایه هد و سرعت پاسخدهی محدود میشود. در بسیاری از موارد، اولین گزینه برای بررسی سلامت اولیه دیسک همین تست است.
2. Extended (Long) Self-Test
-
مدت زمان تقریبی: بین 10 دقیقه تا چند ساعت، بسته به ظرفیت دیسک
-
هدف: بررسی کامل فیزیکی دیسک
-
کاربرد: تحلیل عمیق مشکلات مشکوک یا پیگیری بعد از مشاهده خطای S.M.A.R.T
-
جزئیات بررسی: این تست کل سطح دیسک را اسکن میکند و هر سکتور را از نظر خوانایی و صحت بررسی مینماید. Extended Self-Test میتواند وجود سکتورهای خراب (Bad Sectors)، تاخیر در عملکرد و خطاهای مکانیکی را با دقت بیشتری تشخیص دهد.
3. Conveyance Self-Test (در مدلهای خاص)
-
مدت زمان تقریبی: حدود 5 دقیقه
-
هدف: شناسایی آسیبهایی که ممکن است در هنگام حملونقل فیزیکی به دیسک وارد شده باشد
-
کاربرد: بیشتر در کارخانهها و هنگام ورود قطعه به انبار یا قبل از نصب در سرور
-
جزئیات بررسی: این تست بر ارتعاشات، شوکهای فیزیکی و عدم تعادل داخلی تمرکز دارد که ممکن است به هد یا دیسک آسیب رسانده باشد.
نکته مهم:
در سرورهای نسل جدید HPE، انجام خودکار برخی از این تستها در زمان بوت، پس از مشاهده رفتار مشکوک از سوی سیستم یا به درخواست مدیر سیستم از طریق ابزارهای مدیریتی امکانپذیر است. استفاده از این تستها پیش از تعویض هارد، میتواند در بسیاری موارد خطای نرمافزاری را از خطای سختافزاری تفکیک کند.
در مجموع، شناخت دقیق عملکرد و انواع Self-Test در هاردهای سرورهای HP، به مدیران IT این امکان را میدهد که از سلامت تجهیزات ذخیرهسازی خود اطمینان حاصل کرده و در زمان مناسب، نسبت به تعویض یا نگهداری صحیح آنها اقدام نمایند. این موضوع، پایهای برای حفظ پایداری سرویسها و حفاظت از اطلاعات حیاتی سازمان خواهد بود.
دلایل متداول بروز Self-Test Error در هاردهای HP
گزارش خطای Self-Test Error در هاردهای سرور HP معمولاً بهعنوان یک هشدار جدی تلقی میشود که نشاندهنده احتمال وجود نقص فیزیکی یا منطقی در عملکرد دیسک میباشد. این نوع خطا حاصل شکست یکی از تستهای داخلی S.M.A.R.T است و در صورت نادیده گرفتن، میتواند منجر به از دست رفتن دادهها یا خرابی کامل هارد شود. در این بخش، به بررسی رایجترین علل بروز این خطا در هاردهای مورد استفاده در سرورهای HPE میپردازیم.

HPE HDD bad Sector Error
1. سکتورهای خراب (Bad Sectors)
توضیح فنی:
سکتورهای خراب، نواحیای از سطح دیسک هستند که قابلیت خواندن یا نوشتن داده را از دست دادهاند. این مشکل ممکن است بهدلیل فرسودگی فیزیکی، شوک مکانیکی، یا وقایع محیطی مانند نوسانات برق و گرمای زیاد بهوجود آید.
تأثیر در Self-Test:
در طول Extended Self-Test، هارد دیسک اقدام به خواندن تمامی سکتورها میکند. وجود یک یا چند سکتور غیرقابل خواندن (UNC Errors) باعث شکست تست و تولید پیام Self-Test Error خواهد شد.
راهکار پیشنهادی:
-
بررسی وضعیت هارد با ابزار HPE Smart Storage Administrator (SSA)
-
استفاده از ابزارهای سطح پایین جهت remap سکتورها (در برخی مدلها امکانپذیر است)
-
در صورت تکرار خطا، تعویض هارد دیسک ضروری است.

HDD Physical Error
2. خرابی فیزیکی در دیسک
توضیح فنی:
خرابی در اجزای مکانیکی هارد مانند موتور چرخان (Spindle)، بازوی هد یا صفحات مغناطیسی (Platters) میتواند بهدلیل عمر بالا، نوسانات شدید دما، یا آسیبهای فیزیکی حین نصب یا جابهجایی ایجاد شود.
تأثیر در Self-Test:
در حین اجرای تستها، این خرابیها باعث افزایش غیرطبیعی زمان پاسخدهی (Seek Time) یا ثبت خطاهای مکانیکی (Mechanical Failure) میشوند. گزارشهایی نظیر Read Failure یا Seek Error Rate بالا در لاگ S.M.A.R.T نشانهای از این نوع ایراد است.
راهکار پیشنهادی:
-
بررسی لاگهای iLO و سیستمعامل برای شناسایی الگوهای تکرار خطا
-
جایگزینی سریع هارد برای جلوگیری از خرابی زنجیرهای در RAID

HPE HDD Firmware Error
3. مشکلات در Firmware
توضیح فنی:
فریمور هارد دیسک در واقع سیستم عامل داخلی آن است که وظیفه مدیریت تعامل بین سختافزار و کنترلر را بر عهده دارد. باگها یا ناسازگاریهای فریمور میتواند منجر به بروز خطا در زمان اجرای Self-Test شود، بدون اینکه مشکلی واقعی در ساختار فیزیکی دیسک وجود داشته باشد.
تأثیر در Self-Test:
خطاهای غیرقابل تکرار، ثبت نادرست وضعیت دیسک یا توقف ناگهانی تستها از جمله نشانههای این مشکل هستند.
راهکار پیشنهادی:
-
بررسی آخرین نسخه Firmware از طریق HPE Support Portal
-
بروزرسانی Firmware از طریق HPE SUM (Smart Update Manager) یا iLO
-
استفاده از دیسکهای دارای Firmware تأیید شده و لیستشده در HPE Quickspecs
4. خطای کنترلر RAID یا Backplane
توضیح فنی:
در بسیاری از موارد، خطای Self-Test ممکن است منشأ مستقیم در خود هارد نداشته باشد، بلکه بهدلیل اختلال در عملکرد RAID Controller یا Backplane (سینی اتصال هارد به مادربرد سرور) رخ دهد. این مشکلات معمولاً در اثر اتصالات ناقص، پورتهای معیوب، یا ناسازگاری میان کنترلر و Firmware درایو ایجاد میشوند.
تأثیر در Self-Test:
Self-Test ممکن است بهدرستی شروع نشود یا به صورت ناقص متوقف گردد. همچنین کنترلر ممکن است نتواند دادههای SMART را بهدرستی دریافت یا پردازش کند.
راهکار پیشنهادی:
-
بررسی وضعیت فیزیکی اتصال هاردها و Backplane
-
آپدیت Firmware کنترلر RAID از طریق HPE Smart Update
-
بررسی ناسازگاریهای احتمالی با ابزار HPE Insight Diagnostics
جمعبندی
خطای Self-Test Error در هاردهای سرور HP نشانهای از وجود مشکل واقعی یا بالقوه در عملکرد درایو است که میتواند دلایل متعددی از جمله ایرادات فیزیکی، نرمافزاری یا ارتباطی داشته باشد. شناسایی دقیق منشأ خطا و اقدام بهموقع، از خرابیهای بزرگتر و از دست رفتن دادهها جلوگیری میکند. در این راستا، بهرهگیری از تجربه، ابزارهای تخصصی و پشتیبانی حرفهای شرکت شبکه گستران یاقوت سرخ بهعنوان مرجع تخصصی فروش و خدمات سرورهای HP در ایران، میتواند نقش تعیینکنندهای در حفظ سلامت زیرساختهای سازمانی ایفا کند.
تشخیص و تحلیل خطای Self-Test در هارد سرورهای HP
وقوع خطای Self-Test در هارد سرورهای HP، اگرچه ممکن است برای کاربران غیر متخصص بهصورت یک هشدار ساده ظاهر شود، اما در واقع نشانهای مهم از وجود مشکل در سلامت فیزیکی یا منطقی درایو است. تشخیص بهموقع و تحلیل دقیق این خطا با استفاده از ابزارهای تخصصی HP و استانداردهای صنعتی، میتواند از بروز خرابیهای بحرانی، از دست رفتن اطلاعات و توقف خدمات حیاتی جلوگیری کند. در این بخش، به روشهای جامع برای شناسایی، بررسی و تحلیل خطاهای Self-Test در هاردهای مورد استفاده در سرورهای HPE میپردازیم.

hpe ssa
1. استفاده از ابزار HPE Smart Storage Administrator (SSA)
نقش SSA در تحلیل خطا:
SSA یکی از قدرتمندترین ابزارهای مدیریتی رسمی HP برای مانیتورینگ وضعیت هارد دیسکها و کنترلرهای RAID است. این ابزار در محیط UEFI یا سیستمعامل قابل اجرا بوده و اطلاعات دقیقی از وضعیت درایوها، سلامت کلی، تاریخچه خطاها و نتایج تستهای S.M.A.R.T ارائه میدهد.
قابلیتها:
-
مشاهده نتایج تست داخلی دیسک (Self-Test Results)
-
تحلیل جزئیات خطاها شامل کد، نوع و زمان وقوع
-
اجرای دستی تستهای SMART (Short و Extended)
-
نمایش وضعیت پیشبینیشده خرابی (Predictive Failure)
نکته فنی:
اگر وضعیت یک درایو در SSA به صورت “Imminent Failure” یا “Self-Test Failed” نمایش داده شود، تعویض آن توصیه میشود، حتی در صورت عملکرد ظاهراً عادی.
2. بررسی لاگهای IML در محیط iLO
اهمیت Integrated Management Log (IML):
IML بخشی از زیرساخت مدیریتی iLO در سرورهای HP است که کلیه وقایع مهم سختافزاری از جمله خطاهای هارد دیسک، RAID، پاور، فن و… را ثبت میکند. این لاگها، اطلاعات ارزشمندی درباره زمان، نوع و تعداد دفعات بروز خطا در اختیار مدیران شبکه قرار میدهند.
موارد قابل مشاهده:
-
Self-Test Failure Code (مثلاً: Drive Self-Test Failure on Port X)
-
خطاهای SMART شامل Read Error, Reallocated Sectors
-
پیغامهای مرتبط با Predictive Failure Analysis (PFA)
روش دسترسی:
-
ورود به iLO از طریق مرورگر
-
انتخاب تب “Information” > “Integrated Management Log”
-
ذخیره یا بررسی رکوردهای اخیر
3. ابزارهای عمومی و تخصصی تحلیل S.M.A.R.T
معرفی استاندارد SMART:
SMART (Self-Monitoring, Analysis and Reporting Technology) استانداردی برای مانیتورینگ سلامت هارد است که پارامترهای مهمی مثل نرخ خطای خواندن، تعداد سکتورهای منتقلشده، زمان راهاندازی موتور و… را ثبت و گزارش میدهد.
ابزارهای پیشنهادی:
-
HP Insight Diagnostics: ابزار رسمی برای تست سلامت کامل سیستم و دیسکها
-
smartctl (از بسته smartmontools – مناسب برای لینوکس)
-
CrystalDiskInfo (برای ویندوز، جهت مشاهده لحظهای SMART Attributes)
پارامترهای کلیدی:
-
Reallocated Sector Count
-
Spin Retry Count
-
Current Pending Sector
-
Offline Uncorrectable
تحلیل:
تغییر ناگهانی یا پیوسته این پارامترها نشانهای از افت سلامت فیزیکی دیسک است و حتی بدون Self-Test Error، هشدار جدی محسوب میشود.
4. تمایز بین خطاهای بحرانی و غیر بحرانی
در تحلیل خروجی تستهای Self-Test یا اطلاعات SMART، شناخت تفاوت میان خطاهای بحرانی (Critical) و غیر بحرانی (Non-Critical) ضروری است:
| نوع خطا | ویژگیها | اقدام پیشنهادی |
|---|---|---|
| خطای بحرانی | – شکست تستهای SMART یا Self-Test – هشدار PFA – افزایش شدید خطاها |
تعویض فوری هارد توصیه میشود |
| خطای غیر بحرانی | – نوسانات جزئی در SMART Attributes – خطاهای موقت – تست موفق اما با هشدار |
مانیتورینگ مداوم و بررسی دورهای |
وجود یک خطای غیر بحرانی، اگرچه منجر به توقف فوری سیستم نمیشود، اما در محیطهای Enterprise بهویژه با RAID، ممکن است پیشزمینه خرابی بزرگتر باشد. توصیه میشود وضعیت درایوهای مشکوک بهصورت دورهای و دقیق بررسی شود.
نتیجهگیری
تشخیص و تحلیل دقیق خطای Self-Test در هاردهای سرور HP تنها با استفاده از ابزارهای مناسب و دانش فنی ممکن است. در صورتی که این فرآیند بهدرستی اجرا شود، میتواند از ایجاد اختلال در عملکرد سامانههای حیاتی جلوگیری کرده و هزینههای ناشی از خرابی داده را کاهش دهد. شرکت شبکه گستران یاقوت سرخ با تکیه بر تیم فنی متخصص و دسترسی به ابزارهای رسمی HPE، آماده ارائه خدمات تحلیل سلامت سختافزاری و مشاوره تخصصی در حوزه سرورهای HP میباشد.
راهکارهای پیشنهادی پس از مشاهده Self-Test Error در هارد سرورهای HP
بروز Self-Test Error در هارد دیسکهای سرور HP بهمعنای وجود مشکل جدی در عملکرد یا سلامت فیزیکی درایو است. در محیطهای سازمانی که وابستگی شدیدی به پایداری زیرساختهای ذخیرهسازی وجود دارد، نادیده گرفتن این خطا ممکن است منجر به از دست رفتن اطلاعات، خرابی RAID و توقف سرویس شود. در ادامه، مجموعهای از اقدامات تخصصی و گامبهگام برای مدیریت صحیح این وضعیت ارائه شده است.

Data Backup
1. اقدام سریع برای تهیه نسخه پشتیبان (Backup)
اولویت اول در مواجهه با Self-Test Error، تهیه فوری نسخه پشتیبان از اطلاعات حیاتی است.
-
درایوی که دچار خطای Self-Test شده ممکن است در ظاهر همچنان قابل استفاده باشد، اما احتمال بروز خرابی کامل در کوتاهمدت بسیار زیاد است.
-
در سیستمهایی که از پیکربندی RAID 0 استفاده میکنند، خرابی یک درایو میتواند منجر به از بین رفتن کل مجموعه دادهها شود.
-
پیشنهاد میشود نسخه پشتیبان روی یک محل امن، جدا از زیرساخت فعلی، ذخیره شود (ترجیحاً بهصورت آفلاین یا در فضای ابری قابل اعتماد).
2. بررسی سلامت کلی سیستم ذخیرهسازی
پس از تهیه نسخه پشتیبان، باید سلامت کل زیرساخت ذخیرهسازی مورد ارزیابی دقیق قرار گیرد:
مواردی که باید بررسی شوند:
-
وضعیت سایر درایوها در پیکربندی RAID
-
عملکرد کنترلر RAID و لاگهای مرتبط (از طریق HPE SSA یا IML)
-
دمای عملیاتی هاردها و تهویه مناسب داخل کیس سرور
-
ورژن Firmware هارد و کنترلر (در برخی موارد، بروزرسانی Firmware میتواند مشکلات سازگاری یا گزارشدهی نادرست را رفع کند)
ابزارهای مورد استفاده:
-
HPE Smart Storage Administrator (SSA)
-
HPE Insight Diagnostics
-
iLO Management Engine
3. استفاده از ابزارهای تحلیل بیشتر برای تعیین سطح خطر
اگرچه Self-Test Error نشاندهنده وجود مشکل است، اما سطح خطر ممکن است متفاوت باشد. برای تشخیص دقیقتر:
ابزارهای مکمل:
-
smartctl برای بررسی جزئیات کامل S.M.A.R.T Attributes
-
HPE Insight Diagnostics (Offline Edition) جهت بررسی عمیق سختافزاری
-
HPE iLO IML Log برای مشاهده خطاهای مرتبط ثبتشده در سیستم
چه چیزی باید بررسی شود؟
-
تعداد سکتورهای معیوب (Reallocated / Pending / Uncorrectable)
-
میزان خطاهای خواندن/نوشتن
-
تاریخچه تستهای قبلی و تکرار خطاها
-
تحلیل کدهای خطا و Severity (در ابزار SSA یا لاگهای iLO)
در صورت مشاهده افزایش سریع پارامترهای آسیبپذیر یا وجود چندین خطا در بازه زمانی کوتاه، ریسک از کار افتادن کامل درایو بسیار بالا تلقی میشود.
4. شرایطی که نیاز به تعویض فوری هارد وجود دارد
در برخی شرایط، تعویض درایو بدون هیچ تأخیر توصیه میشود تا از ایجاد اختلال در عملیات و از دست رفتن داده جلوگیری شود:
| وضعیت | شرح | اقدام پیشنهادی |
|---|---|---|
| Self-Test Failed همراه با پیغام Imminent Failure | هارد در آستانه خرابی کامل است | تعویض فوری توصیه میشود |
| وجود Bad Sectors افزایشی در چند روز اخیر | احتمال گسترش خرابی و کندی سیستم | جایگزینی با درایو سالم |
| ثبت خطاهای مکرر در IML یا iLO | ثبت پیوسته خطاهای مشابه یا شدید | ارزیابی و تعویض |
| شکست چندین تست SMART متوالی | نقص فیزیکی یا مکانیکی | خارجسازی فوری از چرخه عملیاتی |
| RAID در وضعیت Degraded و این هارد منبع خرابی است | خطر از بین رفتن کل مجموعه RAID | تهیه Replacement و Rebuild سریع |
نکته مهم:
حتی در صورتی که هارد بهصورت ظاهری کار میکند، ادامه استفاده از یک درایو معیوب میتواند منجر به خرابی مجموعه RAID، کندی شدید، بروز خطا در عملیات Backup/Restore و حتی قفل شدن سیستم شود.
جمعبندی
در صورت مشاهده خطای Self-Test در هاردهای سرور HP، واکنش سریع، اصولی و مستند نقش کلیدی در حفظ اطلاعات و پایداری سیستم ایفا میکند. شرکت شبکه گستران یاقوت سرخ با بهرهگیری از تیم متخصص و دسترسی به هاردها و تجهیزات اورجینال HPE، خدمات تشخیص، آنالیز و جایگزینی فوری درایوهای معیوب را در سریعترین زمان ممکن به مشتریان سازمانی ارائه میدهد.

hpe server hdd replacement
نقش گارانتی و پشتیبانی در مواجهه با خطای Self-Test Error
بروز خطای Self-Test Error در هاردهای سرور HP، بهعنوان یک هشدار سطح بالا از سمت سیستمهای نظارتی مانند HPE Smart Array یا iLO، معمولاً نشانهای از خرابی قریبالوقوع یا آسیب فیزیکی دیسک است. در این شرایط، نقش گارانتی معتبر و خدمات پشتیبانی تخصصی بیش از پیش نمایان میشود؛ چراکه واکنش سریع و اصولی میتواند از بروز آسیبهای بزرگتر در زیرساخت IT سازمان جلوگیری کند.
شرایط استفاده از گارانتی رسمی HPE
محصولات HPE از جمله هارد دیسکهای سرور، در صورت تهیه از منابع معتبر و با شماره سریال رسمی، شامل گارانتی بینالمللی شرکت HP هستند. این گارانتی دارای شرایط مشخصی است که در صورت رعایت آنها، امکان تعویض قطعه معیوب وجود دارد.
مهمترین شرایط استفاده از گارانتی:
-
اصالت کالا: هارد باید دارای سریال معتبر، ثبتشده در سیستم HPE و بدون مخدوش بودن لیبل باشد.
-
عدم آسیب فیزیکی یا دستکاری: هرگونه شکستگی، سوختگی یا باز شدن فیزیکی هارد موجب خروج از شرایط گارانتی خواهد شد.
-
وجود گزارش معتبر خطا: گزارش سیستم (مانند IML یا SSA) باید وجود خطا (مانند Self-Test Error یا Predictive Failure) را بهصورت مستند نشان دهد.
-
قرار داشتن در بازه گارانتی: مدت زمان گارانتی بسته به مدل هارد و قرارداد تأمین متفاوت است (معمولاً ۳ سال برای قطعات پرکاربرد HPE).
توجه: برای استفاده از گارانتی رسمی، فرآیندهای ثبت و درخواست باید مطابق با پروتکلهای جهانی HPE انجام شود که نیازمند همکاری با نمایندگان رسمی یا شرکای دارای صلاحیت در ایران است.

گارانتی یاقوت سرخ
خدمات تخصصی شرکت یاقوت سرخ در زمینه تعویض و پشتیبانی
شرکت شبکه گستران یاقوت سرخ بهعنوان مرکز تخصصی فروش، مشاوره و پشتیبانی تجهیزات سرورهای HPE در ایران، خدمات ویژهای را برای مواجهه با خطاهای بحرانی مانند Self-Test Error ارائه میدهد:
۱. ارزیابی تخصصی خطا و ارائه گزارش فنی
-
تحلیل لاگهای iLO، IML و HPE SSA
-
بررسی S.M.A.R.T. Attributes و وضعیت RAID
-
صدور گزارش رسمی جهت ثبت در فرآیند گارانتی یا RMA
۲. خدمات تعویض سریع و تأمین قطعات اورجینال
-
تأمین هارد دیسک اورجینال HPE با ضمانت اصالت
-
تعویض فوری قطعه معیوب (در صورت تأیید گارانتی یا توافق پشتیبانی)
-
هماهنگی کامل با پیکربندی فعلی سرور (ظرفیت، مدل، سرعت، فرمفکتور)
۳. مشاوره در پیادهسازی راهکار جایگزین بدون توقف سرویس
-
برنامهریزی Hot-Swap یا Cold Replacement بدون از دست رفتن داده
-
اجرای عملیات RAID Rebuild با حداقل ریسک
-
بررسی کلی سلامت زیرساخت ذخیرهسازی برای جلوگیری از بروز خطاهای مشابه
۴. امکان ارائه خدمات SLA-Based
برای سازمانهای حساس که نیاز به پایداری بالا و پاسخ سریع دارند، یاقوت سرخ خدمات مبتنی بر SLA ارائه میکند که شامل موارد زیر است:
-
زمان پاسخ کوتاهتر برای رفع خطا
-
در دسترس بودن قطعات جایگزین در انبار تهران
-
اولویتبندی در پشتیبانی فنی و اعزام کارشناس حضوری
نتیجهگیری
خطای Self-Test Error نشانهای جدی از خرابی احتمالی در هارد سرور است و در چنین شرایطی، داشتن گارانتی معتبر و دسترسی به یک مرکز پشتیبانی تخصصی مانند شرکت یاقوت سرخ، میتواند نقش حیاتی در جلوگیری از توقف خدمات، حفظ دادهها و تضمین سلامت زیرساخت ایفا کند. ارائه تجهیزات اورجینال HPE، همراه با خدمات تحلیل، تعویض و مشاوره تخصصی، از جمله مزایای همکاری با این مجموعه تخصصی به شمار میرود.
پیشگیری از بروز Self-Test Error در هارد سرورهای HPE
خطای Self-Test Error در هارد دیسکهای سرور، معمولاً زمانی رخ میدهد که سیستم مدیریت سختافزاری HPE مانند Smart Array یا iLO، نشانههایی از اختلالات عملکرد یا خرابی قریبالوقوع در دیسک را تشخیص دهد. هرچند این خطا بهطور کامل قابل پیشگیری نیست، اما با رعایت اصول نگهداری، مانیتورینگ و طراحی صحیح زیرساخت، میتوان احتمال وقوع آن را به حداقل رساند و از خرابیهای ناگهانی و از دست رفتن داده جلوگیری کرد.
در ادامه مهمترین راهکارهای پیشگیرانه برای کاهش احتمال بروز Self-Test Error را بررسی میکنیم:

Data Center Temp
۱. استفاده از محیطهای تهویه مناسب
دمای بالای محیط، یکی از عوامل اصلی آسیب به هارد دیسکهای مکانیکی و حتی SSD در مراکز داده است. افزایش دما باعث انبساط اجزای مکانیکی، کاهش روانکاری داخلی و در نهایت بروز خطاهای فیزیکی میشود که در قالب Self-Test Error نمایان خواهند شد.
اقدامات پیشگیرانه:
-
حفظ دمای محیط دیتاسنتر بین ۱۸ تا ۲۷ درجه سانتیگراد
-
استفاده از سیستمهای تهویه و گردش هوای استاندارد در رکها
-
اطمینان از عدم انسداد جریان هوا در مسیر ورودی/خروجی سرورهای HPE
-
بررسی دورهای سلامت فنها و سنسورهای دما از طریق iLO یا HPE Insight
۲. بررسی منظم وضعیت هارد دیسکها
نظارت مداوم بر سلامت دیسکها و رفتار آنها در طول زمان، نقش کلیدی در شناسایی زودهنگام خرابیهای احتمالی دارد. با استفاده از ابزارهای مانیتورینگ سختافزاری HPE، میتوان وضعیت هارد را بهصورت دقیق تحلیل کرد و قبل از بروز خطای بحرانی، برای تعویض آن اقدام نمود.
ابزارها و اقدامات کلیدی:
-
بررسی وضعیت S.M.A.R.T. Attributes از طریق HPE Smart Storage Administrator (SSA)
-
مانیتورینگ پیغامهای IML (Integrated Management Log) در iLO
-
بررسی Reallocated Sectors، CRC Errors، Spin Retry Count
-
راهاندازی Self-Test دستی دورهای برای هاردهای مشکوک
-
برنامهریزی برای تعویض پیشگیرانه هاردهایی که رفتار غیرعادی دارند

hpe server firmware update
۳. بروزرسانی Firmware
عدم بروزرسانی Firmware کنترلرهای RAID یا خود هارد دیسکها میتواند باعث ناهماهنگی نرمافزاری، کاهش سازگاری یا خطاهای خواندن/نوشتن شود که بهمرور زمان در قالب Self-Test Error ظاهر میشوند.
توصیههای فنی:
-
استفاده از ابزار رسمی HPE Service Pack for ProLiant (SPP) برای بروزرسانی
-
بروزرسانی منظم Firmware های زیر:
-
کنترلر RAID (مثل HPE Smart Array P440ar, P816i-a و …)
-
هارد دیسکهای SAS/SATA/SSD با Firmware اختصاصی HPE
-
iLO و BIOS مادربرد سرور
-
توصیه میشود بروزرسانیها فقط توسط کارشناسان دارای صلاحیت انجام شود تا از بروز ناهماهنگی در محیطهای حساس جلوگیری گردد.
۴. استفاده از RAID و راهکارهای افزونگی
استفاده از تکنولوژیهای RAID نهتنها عملکرد ذخیرهسازی را افزایش میدهد، بلکه در زمان بروز خطاهایی مانند Self-Test Error، امکان افزونگی و حفظ دادهها را فراهم میسازد. استفاده از سطوح RAID با تحمل خرابی دیسک، به مدیر سیستم فرصت تعویض هارد معیوب را بدون از دست رفتن دادهها میدهد.
پیشنهادات تخصصی:
-
استفاده از RAID 1, RAID 5 یا RAID 6 برای تحمل خرابی ۱ یا ۲ هارد
-
بهکارگیری RAID + Hot Spare برای جایگزینی خودکار هاردهای معیوب
-
مانیتورینگ RAID Array از طریق ابزارهای HPE مثل SSA یا Insight
-
مستندسازی پیکربندیهای RAID برای بازیابی سریع در شرایط بحرانی
نتیجهگیری
پیشگیری از بروز Self-Test Error نیازمند یک رویکرد چندلایه شامل نگهداری محیطی، مانیتورینگ مداوم، بروزرسانی منظم Firmware و طراحی صحیح سیستمهای افزونگی است. رعایت این موارد باعث میشود زیرساخت ذخیرهسازی شما همیشه در وضعیت پایدار باقی بماند و در صورت بروز اختلال، امکان واکنش سریع و بدون ریسک از دست رفتن داده فراهم باشد.