


مقدمه
در دنیای امروز که داده به عنوان ارزشمندترین دارایی سازمانها شناخته میشود، انتخاب معماری صحیح ذخیرهسازی یکی از حیاتیترین تصمیمات زیرساختی هر تیم IT است. یک انتخاب نادرست میتواند منجر به گلوگاههای عملکردی، هزینههای غیرضروری، یا ناسازگاری با نیازهای عملیاتی سیستم شود.
سه معماری اصلی ذخیرهسازی — Block Storage، File Storage و Object Storage — هرکدام با رویکرد متفاوتی به مسئله دسترسی و مدیریت داده میپردازند. درک عمیق تفاوتهای فنی این سه مدل، پیشنیاز هر تصمیم معماری در حوزه storage است.
این مقاله با رویکردی کاملاً فنی، به بررسی ساختار داخلی، پروتکلهای ارتباطی، مدلهای سازگاری داده، عملکرد و موارد کاربرد هر یک از این معماریها میپردازد و در نهایت راهنمای عملی برای انتخاب مناسبترین گزینه در سناریوهای مختلف ارائه میدهد.
تاریخچه مختصر تکامل Storage
ذخیرهسازی داده از دهه ۱۹۵۰ با نوارهای مغناطیسی آغاز شد. با معرفی هارددیسک در ۱۹۵۶ توسط IBM، دسترسی تصادفی به داده ممکن شد. در دهه ۱۹۸۰، معرفی SCSI و سپس SAN (Storage Area Network) مفهوم Block Storage را به صورت جدی وارد دنیای enterprise کرد.
File Storage با پروتکل NFS از Sun Microsystems در ۱۹۸۴ متولد شد و به سرعت به استاندارد اشتراکگذاری فایل در شبکههای Unix تبدیل گردید. Object Storage نسبتاً جوانتر است؛ Lustre در اوایل ۲۰۰۰ و Amazon S3 در ۲۰۰۶ این پارادایم را وارد دنیای cloud کردند و به سرعت به معماری غالب ذخیرهسازی ابری تبدیل شدند.
مفاهیم پایه: نحوه آدرسدهی داده
در پایهایترین سطح، تفاوت این سه معماری در نحوه آدرسدهی به داده نهفته است:
- Block Storage: داده بر اساس آدرس فیزیکی یا منطقی بلوک (LBA – Logical Block Address) آدرسدهی میشود. سیستمعامل مستقیماً با بلوکهای خام کار میکند.
- File Storage: داده بر اساس path سلسلهمراتبی (مسیر فایل) آدرسدهی میشود. یک namespace مشترک مدیریت دسترسی را انجام میدهد.
- Object Storage: داده بر اساس یک کلید منحصربهفرد (Object Key) در یک فضای تخت (Flat Namespace) آدرسدهی میشود. هیچ سلسلهمراتب واقعی وجود ندارد.
Data Plane در مقابل Control Plane
درک جداسازی data plane و control plane در معماریهای storage اهمیت بالایی دارد:
- Data Plane: مسیر واقعی انتقال داده بین client و storage. در Block Storage این مسیر مستقیم و با کمترین overhead است.
- Control Plane: مدیریت metadata، namespace، دسترسی و orchestration. در Object Storage غنیترین control plane را داریم که شامل lifecycle policies، replication rules و access control است.

Block Storage
معماری داخلی و نحوه کار
Block Storage داده را به بلوکهایی با اندازه ثابت تقسیم میکند — معمولاً ۵۱۲ بایت (sector سنتی) یا ۴ کیلوبایت (Advanced Format). هر بلوک یک آدرس LBA منحصربهفرد دارد و سیستمعامل از طریق device driver مستقیماً با این بلوکها تعامل میکند.
در این مدل، هیچ فایلسیستمی در سطح storage device وجود ندارد. سیستمعامل client مسئول ایجاد و مدیریت فایلسیستم (ext4، NTFS، XFS و…) روی بلوکهای خام است. این موضوع به block storage بالاترین درجه انعطاف و کنترل را میدهد.
در محیطهای SAN (Storage Area Network)، بلوکها از طریق شبکه اختصاصی Fibre Channel یا iSCSI در دسترس قرار میگیرند. در محیطهای مدرن NVMe، پروتکل NVMe-oF (NVMe over Fabrics) تأخیر را به حداقل ممکن کاهش داده است.
پروتکلها
iSCSI (Internet Small Computer System Interface)
iSCSI پروتکل SCSI را روی TCP/IP اجرا میکند و امکان استفاده از زیرساخت شبکه Ethernet موجود را برای دسترسی به Block Storage فراهم میکند. کمهزینهترین گزینه برای پیادهسازی SAN است اما overhead پروتکلهای شبکه معمولی، تأخیر بیشتری نسبت به Fibre Channel ایجاد میکند.
Fibre Channel (FC)
Fibre Channel یک پروتکل اختصاصی برای SAN است که شبکه ذخیرهسازی کاملاً جداگانهای از LAN ایجاد میکند. با تأخیر زیر میلیثانیه و throughput بالا، انتخاب اول برای workloadهای mission-critical در enterprise است. HPE با محصولاتی نظیر HPE 3PAR StoreServ و HPE Primera از FC پشتیبانی کامل دارد.
NVMe-oF (NVMe over Fabrics)
NVMe-oF جدیدترین استاندارد است که پروتکل NVMe بهینهشده برای Flash را از PCIe bus داخلی به شبکه (RoCE، FC-NVMe یا iWARP) گسترش میدهد. با تأخیر در حد چند میکروثانیه و IOPS بسیار بالا، مناسبترین گزینه برای workloadهای فشرده I/O نظیر in-memory databases است.
مکانیزمهای Replication و HA
Block Storage در enterprise معمولاً از مکانیزمهای زیر برای high availability استفاده میکند:
- Synchronous Replication: هر write operation همزمان روی دو یا چند سایت نوشته میشود. RPO = 0 اما با تأخیر بیشتر.
- Asynchronous Replication: دادهها با تأخیر قابل تنظیم به سایت ثانویه منتقل میشوند. RPO > 0 اما تأخیر کمتری در سایت اصلی.
- RAID: در سطح دیسک، RAID 5/6/10 برای محافظت در برابر خرابی دیسک استفاده میشود.
- Multipathing: چندین مسیر فیزیکی به storage برای HA و load balancing.
پیادهسازیهای رایج
- HPE Primera و HPE 3PAR StoreServ: راهکارهای enterprise-grade با قابلیتهای پیشرفته.
- HPE Nimble Storage: با تکنولوژی InfoSight برای پیشبینی مشکلات با هوش مصنوعی.
- Amazon EBS (Elastic Block Store): block storage ابری AWS.
- Ceph RBD (RADOS Block Device): پیادهسازی open-source با مقیاسپذیری بالا.
- VMware vSAN: block storage هایپرکانورجد برای محیطهای VMware.
موارد استفاده ایدهآل
- دیتابیسهای رابطهای (MySQL، PostgreSQL، Oracle، SQL Server).
- ذخیرهسازی دیسک ماشینهای مجازی (VM disk images).
- سیستمعامل و boot volumes.
- In-memory databases نظیر SAP HANA که نیاز به Persistent Memory دارند.
- هر workload که نیاز به IOPS بالا و Latency زیر میلیثانیه دارد.

File Storage
معماری داخلی و نحوه کار
File Storage یک لایه abstraction بالاتر از block storage قرار دارد. دادهها در قالب فایلها و دایرکتوریها سازماندهی میشوند و یک namespace مشترک از طریق شبکه در اختیار چندین client به طور همزمان قرار میگیرد.
قلب File Storage یک NAS (Network-Attached Storage) یا File Server است که یک فایلسیستم توزیعشده را مدیریت میکند. Clientها از طریق پروتکلهای شبکه (NFS یا SMB) به فایلها دسترسی مییابند و سیستم به صورت شفاف تمام عملیات lock، caching و consistency را مدیریت میکند.
یکی از مزایای کلیدی File Storage، POSIX compliance آن است. POSIX (Portable Operating System Interface) مجموعهای از استانداردها برای سیستمعاملهای Unix-like است که شامل عملیاتی نظیر locking، permission و atomic operations میشود. بسیاری از نرمافزارهای Linux-native نیاز به POSIX-compliant filesystem دارند.
پروتکلها
NFS (Network File System) v3 و v4
NFS پروتکل اصلی اشتراکگذاری فایل در محیطهای Unix/Linux است. نسخه ۴ (NFSv4) بهبودهای قابل توجهی نسبت به v3 ارائه میدهد: عملیات compound (کاهش round-trip)، session-based connections، پشتیبانی بهتر از firewall، و delegation برای بهبود کارایی cache.
SMB/CIFS (Server Message Block)
SMB پروتکل اصلی اشتراکگذاری فایل در محیطهای Windows است. SMB3 (Windows Server 2012+) قابلیتهای مهمی نظیر SMB Direct (RDMA)، SMB Multichannel (استفاده از چندین NIC) و رمزنگاری end-to-end را اضافه کرده است.
POSIX Interface
در محیطهای distributed file system، POSIX API مستقیماً در سطح client library پیادهسازی میشود. Lustre و GPFS/Spectrum Scale از این روش برای ارائه دسترسی با کارایی بالا در محیطهای HPC استفاده میکنند.
File Locking و Concurrency
یکی از چالشهای اصلی در File Storage مدیریت همزمانی است. هنگامی که چندین client به طور همزمان به یک فایل دسترسی دارند، باید مکانیزمی برای جلوگیری از corruption وجود داشته باشد:
- Advisory Locks: در NFS سنتی، lockها توصیهای (advisory) هستند و clientها میتوانند آنها را نادیده بگیرند.
- Mandatory Locks: در SMB، lockها اجباری (mandatory) هستند و سرور دسترسی متعارض را بلاک میکند.
- Distributed Locking در NFSv4: یک مکانیزم lease-based که lockها را با سرور هماهنگ میکند.
پیادهسازیهای رایج
- HPE MSA Storage: راهکار مقرونبهصرفه برای SMB و enterprise کوچک.
- NetApp ONTAP: پلتفرم NAS پیشرفته با قابلیتهای dedup و compression.
- Amazon EFS (Elastic File System): NFS مدیریتشده ابری AWS با مقیاسپذیری خودکار.
- GlusterFS: Distributed file system متنباز با قابلیت اجرا روی commodity hardware.
- Lustre: فایلسیستم توزیعشده با کارایی بسیار بالا برای محیطهای HPC.
موارد استفاده ایدهآل
- Home directory و roaming profiles کاربران.
- محیطهای collaborative که چندین کاربر به فایلهای مشترک نیاز دارند.
- Content Management System (CMS) و media servers.
- لاگهای متمرکز و shared logging در خوشههای سرور.
- محیطهای HPC که نیاز به parallel file access دارند.

Object Storage
معماری داخلی و نحوه کار
Object Storage اساساً با دو معماری قبلی متفاوت است. دادهها در قالب object نگهداری میشوند که هر کدام شامل سه بخش است: داده (data)، متادیتا (metadata) و یک شناسه منحصربهفرد (Object ID یا Key).
مهمترین ویژگی معماری Object Storage، namespace تخت (Flat Namespace) آن است. در حالی که File Storage یک ساختار درختی دایرکتوری دارد، در Object Storage تمام objectها در یک سطح در bucketها قرار دارند. ساختار پوشهای که در S3 میبینیم (مثلاً s3://bucket/folder/file.txt) در واقع بخشی از نام key است و یک سلسلهمراتب واقعی نیست.
متادیتا در Object Storage بسیار غنیتر از file metadata معمولی است. علاوه بر اطلاعات پایه نظیر اندازه و تاریخ، میتوان metadata دلخواه (custom metadata) را نیز به هر object الصاق کرد. این قابلیت امکان پیادهسازی lifecycle policies پیچیده، content routing و data classification را فراهم میکند.
Consistency Model
Object Storage معمولاً از مدل Eventual Consistency استفاده میکند، هرچند پیادهسازیهای مدرن (از جمله AWS S3 از نوامبر ۲۰۲۰) به Strong Consistency رسیدهاند:
- Strong Consistency: پس از عملیات write موفق، هر read بعدی مقدار جدید را برمیگرداند.
- Eventual Consistency: پس از write، ممکن است readهای بلافاصله بعدی مقدار قدیمی را برگردانند. در نهایت همه nodeها به مقدار یکسان همگرا میشوند.
در سیستمهای توزیعشده، طبق CAP Theorem، نمیتوان همزمان Consistency، Availability و Partition Tolerance را داشت. Object Storage معمولاً AP (Availability + Partition Tolerance) را انتخاب میکند که این انتخاب مقیاسپذیری افقی بینهایت را ممکن میسازد.
پروتکلها
Amazon S3 API
S3 API به استاندارد de facto در Object Storage تبدیل شده است. تقریباً تمام پیادهسازیهای مدرن Object Storage از S3 API پشتیبانی میکنند که به معنای portability بالا و ecosystem گسترده ابزارها و کتابخانهها است.
OpenStack Swift API
Swift API پروتکل اصلی OpenStack Object Storage است. در محیطهای private cloud مبتنی بر OpenStack رایج است اما S3 API به دلیل ecosystem گستردهتر، محبوبیت بیشتری دارد.
Erasure Coding در مقابل Replication
برای durability، Object Storage از دو روش اصلی استفاده میکند:
- Replication: هر object در چندین node کپی میشود (معمولاً ۳ کپی). ساده اما overhead ذخیرهسازی ۳۰۰٪ است.
- Erasure Coding: داده به chunks تقسیم و به همراه parity chunks در nodeهای مختلف توزیع میشود. مثلاً در طرح ۸+۴، از ۱۲ chunk میتوان تا ۴ chunk را از دست داد. overhead ذخیرهسازی ۱۵۰٪ با durability مشابه replication سهگانه. HPE Cray ClusterStor و Ceph از Erasure Coding پشتیبانی میکنند.
پیادهسازیهای رایج
- Amazon S3: بزرگترین Object Storage ابری با SLA 99.999999999٪ (11 nine) durability.
- MinIO: پیادهسازی متنباز با S3 API، مناسب برای private cloud و on-premise.
- Ceph RADOS: پلتفرم unified storage که Block، File و Object را همزمان ارائه میدهد.
- HPE Cray ClusterStor: راهکار HPE برای Object Storage در مقیاس exabyte.
- Azure Blob Storage و Google Cloud Storage: رقبای اصلی S3 در فضای ابری.
موارد استفاده ایدهآل
- Backup و Disaster Recovery با نگهداری طولانیمدت.
- Data Lake و ذخیره raw data برای analytics.
- CDN origin و توزیع محتوای static (images، videos، JS، CSS).
- ML/AI datasets و model artifacts.
- Log archiving و compliance storage.
- Software distribution و package repositories.
مقایسه فنی عمیق
جدول زیر مقایسه جامع سه معماری ذخیرهسازی را از ابعاد مختلف نشان میدهد:
| ویژگی | Block Storage | File Storage | Object Storage | توضیح |
| ساختار داده | بلوکهای خام ثابت | فایل / پوشه سلسلهمراتبی | Object با متادیتا و ID | نحوه سازماندهی داده |
| پروتکل دسترسی | iSCSI، FC، NVMe-oF | NFS، SMB/CIFS، POSIX | HTTP/REST، S3 API | رابط ارتباطی |
| تأخیر (Latency) | بسیار پایین (< 1ms) | پایین تا متوسط | متوسط تا بالا | عملکرد زمانی پاسخ |
| IOPS | بسیار بالا | متوسط | پایین | تعداد عملیات I/O در ثانیه |
| Throughput | بالا | متوسط | بالا (برای فایلهای بزرگ) | نرخ انتقال داده |
| مقیاسپذیری | محدود (Vertical) | متوسط | بینهایت (Horizontal) | قابلیت توسعه |
| Consistency Model | Strong Consistency | Strong Consistency | Eventual Consistency | مدل سازگاری داده |
| هزینه | بالا | متوسط | پایین | TCO نسبی |
| مثالهای رایج | AWS EBS، HPE 3PAR، SAN | NAS، AWS EFS، GlusterFS | AWS S3، MinIO، Ceph | پیادهسازیهای شناختهشده |
| کاربرد اصلی | Database، VM، OS | Shared FS، Home Dir | Backup، Media، Data Lake | سناریوهای ایدهآل |
تحلیل Performance
در بررسی عملکرد، سه معیار اصلی وجود دارد که برای workloadهای مختلف اولویت متفاوتی دارند:
IOPS (Input/Output Operations Per Second)
IOPS معیار تعداد عملیات خواندن/نوشتن در ثانیه است. Block Storage با دسترسی مستقیم به دیسک بدون overhead شبکه یا فایلسیستم توزیعشده، بالاترین IOPS را ارائه میدهد. NVMe enterprise-grade میتواند بیش از یک میلیون IOPS داشته باشد. File Storage به دلیل overhead پروتکلهای NFS/SMB، IOPS کمتری نسبت به Block Storage دارد. Object Storage پایینترین IOPS را دارد چون هر عملیات از طریق HTTP/REST انجام میشود.
Throughput (Bandwidth)
Throughput میزان داده منتقلشده در واحد زمان است. Object Storage در sequential read/write فایلهای بزرگ میتواند throughput بسیار بالایی داشته باشد چون data path ساده است و هیچ lock یا coordination پیچیدهای وجود ندارد. Block Storage نیز throughput بالایی دارد. File Storage در throughput محدودیتهایی دارد که به جنس workload وابسته است.
Latency (تأخیر)
Latency زمان پاسخ به یک عملیات منفرد است. Block Storage کمترین تأخیر را دارد. File Storage تأخیر بیشتری به دلیل overhead پروتکل شبکه دارد اما برای اکثر کاربردها قابل قبول است. Object Storage بالاترین تأخیر را دارد چون هر عملیات یک HTTP transaction کامل است.
مقایسه Consistency Models
مدل سازگاری داده تأثیر مستقیم بر رفتار سیستم در سناریوهای همزمانی و failover دارد:
- Block Storage: Strong Consistency در سطح block. سیستمعامل و فایلسیستم لایههای caching و journaling را مدیریت میکنند.
- File Storage: معمولاً Strong Consistency با file-level locking. NFSv4 lease-based consistency را ارائه میدهد. در محیطهای distributed ممکن است cache coherency challenges وجود داشته باشد.
- Object Storage: تاریخاً Eventual Consistency، اما پیادهسازیهای مدرن به Strong Consistency رسیدهاند. با این حال، در برخی عملیاتهای پیچیده (مثل list operations) هنوز ممکن است inconsistency موقت وجود داشته باشد.
مقایسه Durability و Availability
این دو معیار اغلب با هم اشتباه گرفته میشوند:
- Durability: احتمال از دست ندادن داده در طول زمان. AWS S3 معروفترین مثال با ۱۱ نه (99.999999999٪) durability است.
- Availability: درصد زمانی که سیستم در دسترس است. معمولاً ۹۹.۹٪ تا ۹۹.۹۹٪ SLA.
Object Storage به دلیل توزیع داده در nodeهای متعدد با Erasure Coding، بالاترین durability را دارد. Block Storage در SAN enterprise با synchronous replication نیز durability بسیار بالایی دارد. File Storage در NAS enterprise معمولاً از RAID و replication ترکیبی استفاده میکند.
سناریوهای واقعی و تصمیمگیری
جدول راهنمای تصمیم
| نیاز پروژه | معماری پیشنهادی | دلیل |
| اجرای OLTP Database با تراکنش بالا | Block Storage | IOPS بالا و Latency پایین ضروری است |
| اشتراکگذاری فایل بین سرورهای متعدد | File Storage | POSIX semantics و shared access |
| ذخیرهسازی backup و آرشیو | Object Storage | هزینه پایین و مقیاسپذیری بالا |
| اجرای Virtual Machines | Block Storage | نیاز به دسترسی مستقیم به دیسک |
| CDN و توزیع محتوای media | Object Storage | HTTP access و متادیتای غنی |
| CI/CD و build artifacts | Object Storage | REST API و versioning آسان |
| Analytics و Data Lake | Object Storage | حجم بالا و دسترسی موازی |
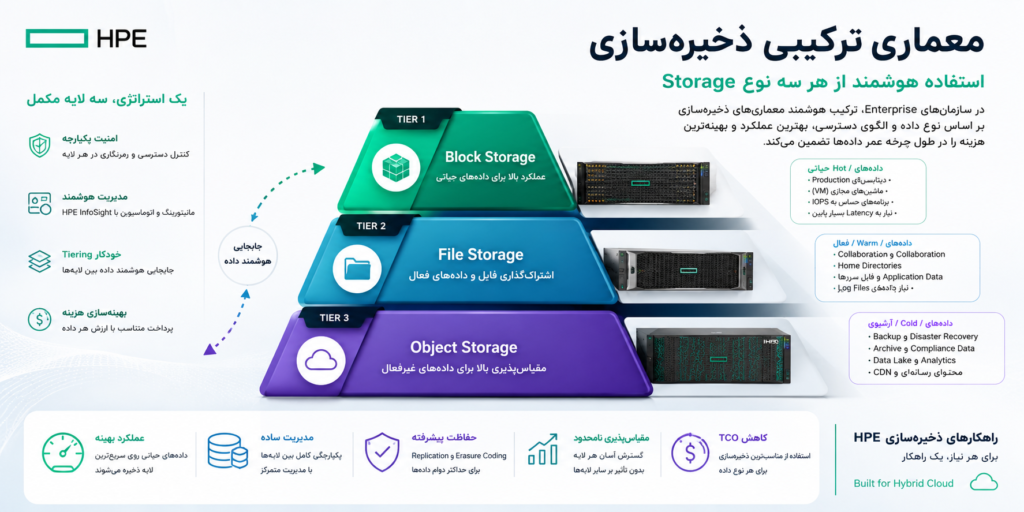
معماری ترکیبی (Hybrid Storage)
در اکثر سازمانهای enterprise، نیازی به انتخاب یک معماری واحد وجود ندارد. رویکرد بهینه ترکیب هوشمند هر سه معماری بر اساس نوع داده و الگوی دسترسی است:
- Tier 1 — Block Storage برای hot data: دیتابیسهای production، VMهای critical، workloadهایی که به IOPS بالا نیاز دارند.
- Tier 2 — File Storage برای warm data: فایلهای shared، home directories، logهای اخیر، محیطهای collaborative.
- Tier 3 — Object Storage برای cold data: backup، archive، compliance data، datasets بزرگ که به ندرت خوانده میشوند.
HPE با راهکار HPE InfoSight و HPE Cloud Volumes امکان مدیریت یکپارچه این لایههای مختلف storage را فراهم میکند و میتوان data tiering را به صورت خودکار بر اساس pattern دسترسی تنظیم کرد.
ملاحظات امنیتی
Block Storage
- رمزنگاری در سطح volume (Full Disk Encryption یا Software-based).
- کنترل دسترسی از طریق iSCSI CHAP authentication یا Fibre Channel zoning.
- HPE 3PAR و Primera از AES-256 encryption at rest پشتیبانی میکنند.
File Storage
- ACL (Access Control List) در سطح فایل و دایرکتوری.
- Kerberos authentication برای NFS و SMB.
- رمزنگاری در transit با NFSv4.1 و SMB3 encryption.
Object Storage
- Bucket policies و IAM-style access control.
- Server-Side Encryption (SSE) و Client-Side Encryption.
- Object Lock و WORM (Write Once Read Many) برای compliance.
- Pre-signed URLs برای دسترسی موقت و محدود.
چکلیست انتخاب معماری
سوالات کلیدی
پیش از انتخاب معماری storage، پاسخ به سوالات زیر الزامی است:
- آیا نرمافزار شما نیاز به POSIX-compliant filesystem دارد؟ اگر بله، Block یا File Storage.
- آیا چندین سرور یا کاربر باید همزمان به داده دسترسی داشته باشند؟ اگر بله، File Storage.
- IOPS مورد نیاز workload چقدر است؟ بالای ۱۰,۰۰۰ IOPS؟ Block Storage.
- آیا دادهها بیشتر Write-Once/Read-Many هستند؟ Object Storage.
- آیا نیاز به نگهداری متادیتای غنی و custom metadata دارید؟ Object Storage.
- آیا به HTTP/REST API برای دسترسی از روی اینترنت نیاز دارید؟ Object Storage.
- بودجه و TCO مجاز چقدر است؟ Object کمترین، Block بیشترین هزینه.
- آیا نیاز به global distribution و geo-replication دارید؟ Object Storage.
Performance Sizing
هنگام تعیین ظرفیت storage، علاوه بر حجم خام، فاکتورهای زیر را در نظر بگیرید:
- IOPS budget: تعداد تراکنشهای database در ثانیه ضربدر IOPS per transaction.
- Throughput requirement: حجم دادهای که در peak hours باید جابجا شود.
- Latency SLA: حداکثر تأخیر قابل قبول برای end-user experience.
- Growth rate: رشد پیشبینیشده داده در ۱، ۳ و ۵ سال آینده.
- Data reduction ratio: ضریب dedup و compression مورد انتظار.
نقشه جامع پورتفولیوی ذخیرهسازی HPE
پورتفولیوی راهکارهای ذخیرهسازی HPE در سال ۲۰۲۵ بر اساس نوع سرویس، معماری و کاربرد به چند خانواده اصلی تقسیم میشود. هر خانواده برای پاسخگویی به نیازهای متفاوت سازمانها، از کسبوکارهای کوچک گرفته تا مراکز داده، محیطهای ابری و ابررایانهها طراحی شده است.
خانواده HPE Alletra Storage MP؛ پرچمدار راهکارهای ذخیرهسازی

HPE Alletra Storage MP B10000 | Block + File
Alletra Storage MP B10000 پیشرفتهترین پلتفرم ذخیرهسازی بلاک و فایل HPE است که بر پایه معماری Disaggregated توسعه یافته است. این محصول بهعنوان نخستین راهکار Scale-Out Block Storage صنعت با ضمانت ۱۰۰ درصد دسترسپذیری دادهها (Data Availability) شناخته میشود.
این سیستم از پردازندههای AMD EPYC بهره میبرد و با استفاده از فناوری NVMe-over-TCP امکان ارائه سرویسهای Block و File را روی یک بستر سختافزاری واحد فراهم میکند.
کاربردهای اصلی
- پایگاههای داده Mission-Critical
- زیرساختهای مجازیسازی (VM)
- برنامههای Cloud-Native
- پردازشهای هوش مصنوعی و Machine Learning
HPE Alletra Storage MP X10000 | Object + File
Alletra Storage MP X10000 یک راهکار Software-Defined مبتنی بر Kubernetes با معماری Containerized است که برای مدیریت حجم عظیم دادههای بدون ساختار طراحی شده است.
این محصول علاوه بر پشتیبانی بومی از Object Storage از طریق APIهای S3 و S3a، امکان ارائه File Storage مبتنی بر NFSv4.1 را نیز فراهم میکند. همچنین قابلیت Bucket-Level Replication میان چندین سیستم X10000 را در اختیار سازمانها قرار میدهد.
کاربردهای اصلی
- Data Lake
- ذخیرهسازی دادههای هوش مصنوعی
- Backup در مقیاس پتابایت
- تحلیل بلادرنگ دادهها (Real-Time Analytics)
- خطوط پردازش AI و ML

HPE GreenLake File Storage | File
GreenLake File Storage بر پایه سختافزار خانواده Alletra Storage MP توسعه یافته و از نرمافزار VAST Data (بهصورت OEM) برای ارائه سرویس File Storage استفاده میکند.
این راهکار برای سازمانهایی طراحی شده است که به دسترسی فایل در مقیاس Enterprise همراه با قابلیت Scale-Out و کارایی بسیار بالا نیاز دارند.
کاربرد اصلی
- Workloadهای Data-Intensive و دسترسی فایل در مقیاس سازمانی

HPE MSA Storage | Block + File
خانواده HPE MSA اقتصادیترین راهکار ذخیرهسازی HPE محسوب میشود و برای کسبوکارهای کوچک و متوسط (SMB) و سازمانهایی با بودجه محدود طراحی شده است.
این خانواده در کنار محصولاتی مانند StoreOnce، کتابخانههای نواری MSL، Zerto و SimpliVity بخشی از سبد کامل راهکارهای ذخیرهسازی HPE را تشکیل میدهد.
کاربرد اصلی
- ذخیرهسازی سازمانی برای شرکتهای کوچک و متوسط
HPE StoreOnce | Backup & Deduplication
StoreOnce راهکار تخصصی HPE برای پشتیبانگیری، نگهداری بلندمدت اطلاعات و افزایش Cyber Resilience است.
این محصول با استفاده از فناوری پیشرفته Deduplication، حجم دادههای تکراری را کاهش داده و فضای ذخیرهسازی موردنیاز برای Backup را به شکل قابلتوجهی کم میکند.
کاربردهای اصلی
- Backup سازمانی
- Disaster Recovery
- آرشیو بلندمدت اطلاعات
HPE ClusterStor | File Storage برای HPC
ClusterStor راهکار اختصاصی HPE برای محیطهای ابررایانشی (HPC) و Supercomputing است.
این محصول در پروژههای بزرگ تحقیقاتی و مراکز ابررایانه جهان، از جمله Oak Ridge National Laboratory و Los Alamos National Laboratory، مورد استفاده قرار گرفته و در آزمونهای IO500 نیز عملکرد بسیار بالایی از خود نشان داده است.
کاربردهای اصلی
- ابررایانهها
- محاسبات علمی
- محیطهای HPC با نیاز به پهنای باند بسیار بالا
پورتفولیوی ذخیرهسازی HPE تقریباً تمام نیازهای سازمانی را پوشش میدهد؛ از ذخیرهسازی اقتصادی برای شرکتهای کوچک گرفته تا زیرساختهای Enterprise، هوش مصنوعی، Data Lake، Backup و ابررایانهها. در این میان، خانواده Alletra Storage MP بهعنوان محور اصلی استراتژی ذخیرهسازی HPE شناخته میشود و بخش عمده سرمایهگذاری این شرکت بر توسعه همین پلتفرم متمرکز است.
همچنین HPE در نوامبر ۲۰۲۵ اعلام کرد عرضه برخی راهکارهای نرمافزاری شرکتهای ثالث مانند Qumulo، Scality و WEKA را متوقف کرده و تمرکز خود را بر توسعه محصولات مبتنی بر فناوریهای داخلی، بهویژه خانواده Alletra، قرار داده است.
جمعبندی
هر سه معماری ذخیرهسازی — Block، File و Object Storage — ابزارهای قدرتمندی هستند که برای مسائل متفاوتی طراحی شدهاند. هیچکدام به تنهایی «بهترین» نیست؛ انتخاب صحیح به ماهیت workload، نیازهای عملکردی، الگوهای دسترسی و محدودیتهای بودجهای بستگی دارد.
Block Storage همچنان بهترین انتخاب برای workloadهای I/O-intensive نظیر دیتابیسها و ماشینهای مجازی است. فناوریهای جدید نظیر NVMe-oF مرز عملکردی آن را به سطوح جدیدی رساندهاند که پیش از این غیرممکن به نظر میرسید.
File Storage با پروتکلهای استاندارد NFS و SMB، راهکار بلوغیافتهای برای اشتراکگذاری داده در محیطهای enterprise است. در محیطهای HPC، distributed file systems نظیر Lustre مرزهای throughput را جابجا کردهاند.
Object Storage با ظهور cloud computing به پارادایم غالب ذخیرهسازی دادههای unstructured تبدیل شده است. مقیاسپذیری نزدیک به بینهایت، هزینه پایین و ecosystem غنی آن را برای data lake، backup و توزیع محتوا بیرقیب کرده است.
در دنیای واقعی enterprise، معماری ترکیبی (Hybrid Storage Tiering) با استفاده هوشمند از هر سه نوع بر اساس نوع داده و lifecycle آن، بهینهترین رویکرد است. HPE با پورتفولیوی گستردهای از راهکارهای storage در تمام این سه حوزه، امکان پیادهسازی یک استراتژی جامع و یکپارچه storage را برای سازمانها فراهم میکند.
































