

آغاز عصری نوین در پردازشهای سنگین با نقشآفرینی GPU
در دهههای گذشته، پردازندههای مرکزی (CPU) همواره قلب تپندهی سیستمهای کامپیوتری محسوب میشدند؛ مسئول اجرای دستورات سیستمعامل، مدیریت ورودی/خروجی، و انجام پردازشهای منطقی. با این حال، ظهور نیازهای جدید در حوزههایی همچون هوش مصنوعی (AI)، یادگیری ماشین (Machine Learning)، تحلیل دادههای عظیم (Big Data Analytics) و شبیهسازیهای پیشرفتهی علمی، چالشهایی ایجاد کرده که معماری سنتی CPU بهتنهایی قادر به پاسخگویی مؤثر به آنها نیست.
در این میان، پردازندههای گرافیکی (GPU)، که در ابتدا برای رندر گرافیک و بازیهای رایانهای طراحی شده بودند، بهتدریج به ابزارهای قدرتمند و تخصصی در پردازشهای عددی پیچیده و گسترده تبدیل شدهاند. این تحول بهویژه در مراکز داده (Data Centers)، زیرساختهای ابری (Cloud Platforms) و سیستمهای پیشرفتهی سروری که شرکتهایی مانند Hewlett Packard Enterprise (HPE) ارائه میدهند، مشهود است.
شرکتهایی که در زمینه تأمین تجهیزات سرور و سختافزارهای پردازشی پیشرفته فعالیت دارند – از جمله شبکه گستران یاقوت سرخ بهعنوان مرکز تخصصی فروش و پشتیبانی سرورهای HPE در ایران – باید به این تحول بنیادی در معماری پردازشی توجه ویژهای داشته باشند. زیرا انتخاب بین CPU و GPU، یا ترکیب هوشمندانهی آنها، میتواند بهصورت مستقیم بر کارایی، مقیاسپذیری و هزینههای عملیاتی سازمانها تأثیر بگذارد.
سوال کلیدی: آیا GPU جایگزین CPU خواهد شد؟
پیشرفت خیرهکنندهی GPU در انجام محاسبات همزمان (Parallel Computing) و تسریع مدلهای یادگیری عمیق، این سؤال را برای بسیاری از متخصصان فناوری اطلاعات و مدیران زیرساختهای پردازشی بهوجود آورده است:
«آیا GPU بهزودی جایگزین CPU در پردازشهای سنگین خواهد شد؟»
پاسخ به این پرسش، نیازمند بررسی دقیق تفاوتهای معماری، موارد کاربرد، مزایا و محدودیتهای هر دو نوع پردازنده است. این مقاله با هدف بررسی دقیق این موضوع و تبیین نقش روزافزون GPU در محیطهای حرفهای، از جمله سرورهای پیشرفتهی HPE، به نگارش درآمده است. در ادامه با ما همراه باشید تا بهصورت تخصصی این روند تحولآفرین در دنیای پردازش را واکاوی کنیم.
GPU architecture vs CPU architecture
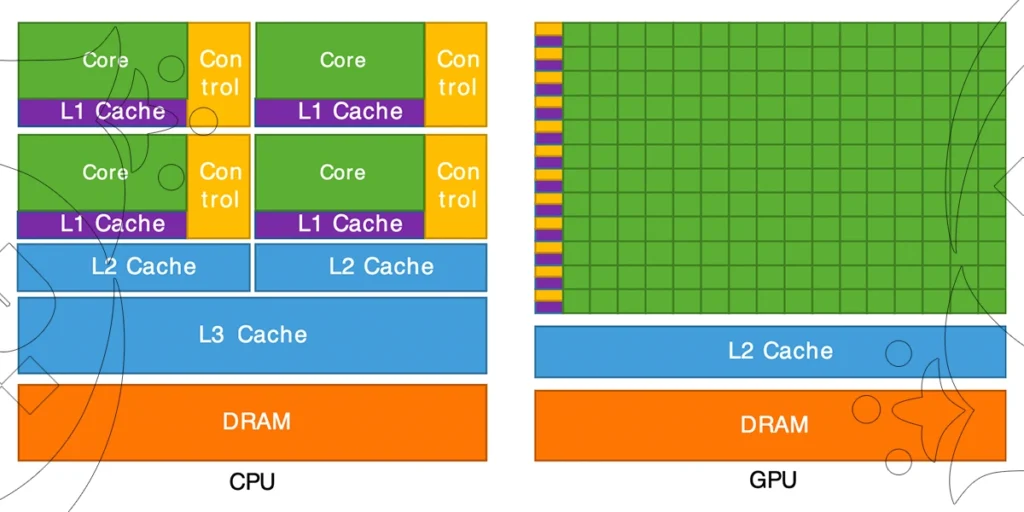
مقایسه معماری CPU و GPU: دو رویکرد بنیادین در دنیای پردازش
درک تفاوتهای معماری بین پردازنده مرکزی (CPU) و پردازنده گرافیکی (GPU)، برای انتخاب صحیح سختافزار در پروژههای پردازشی سازمانی، نقش کلیدی دارد. هر یک از این پردازندهها با اهداف و ویژگیهای متفاوت طراحی شدهاند و شناخت ساختار درونی آنها به مدیران فناوری اطلاعات، تحلیلگران داده و تصمیمگیران حوزه زیرساخت کمک میکند تا بهرهوری سیستمها را بهینهسازی کنند.
۱. تعریف CPU و GPU
CPU (Central Processing Unit):
CPU، که بهعنوان «مغز رایانه» شناخته میشود، یک پردازندهی همهکاره است که وظیفه اجرای دستورالعملهای عمومی سیستمعامل و نرمافزارها را بر عهده دارد. این پردازندهها برای انجام پردازشهای ترتیبی، تصمیمگیری منطقی، و کنترل جریان داده طراحی شدهاند.
GPU (Graphics Processing Unit):
GPU در ابتدا برای پردازش سریع تصاویر و گرافیک طراحی شد. اما ساختار خاص آن، یعنی توانایی اجرای تعداد زیادی عملیات همزمان (Parallel Computing)، باعث شد بهسرعت جایگاه ویژهای در حوزههایی نظیر یادگیری ماشین، رندر سهبعدی، تحلیل علمی و دادهکاوی پیدا کند.
۲. ساختار معماری: تفاوت در طراحی و عملکرد
| ویژگیها | CPU | GPU |
|---|---|---|
| تعداد هسته | ۴ تا ۶۴ (در سرورهای مدرن، مانند HPE DL380) | صدها تا هزاران هسته کوچک (مثلاً NVIDIA A100) |
| نوع هسته | قدرتمند، همهمنظوره | ساده، سبک و تخصصی در پردازش موازی |
| حافظه کش (Cache) | L1، L2، L3 با اندازه زیاد و تأخیر کم | کش محدودتر و سریعتر، با تمرکز بر پهنای باند بالا |
| مدیریت منابع | مستقل، پیشرفته، با کنترل دقیق | وابسته به CPU برای مدیریت وظایف و برنامهریزی |
| توان مصرفی | بهینه شده برای مصرف عمومی | مصرف بالا در عملیات سنگین پردازشی |
در معماری CPU، تمرکز بر کارایی هستههای تکی و برنامهریزی دقیق منابع سیستم است. در مقابل، GPU دارای هزاران هستهی ساده است که بهطور همزمان روی دادههای مشابه عملیات انجام میدهند؛ این ویژگی برای الگوریتمهای مبتنی بر ماتریس، نظیر مدلهای هوش مصنوعی، بسیار کارآمد است.
بیشتر بخوانید: معرفی خدمات HPE Data Sanitization ، راهکاری برای حفظ امنیت اطلاعات
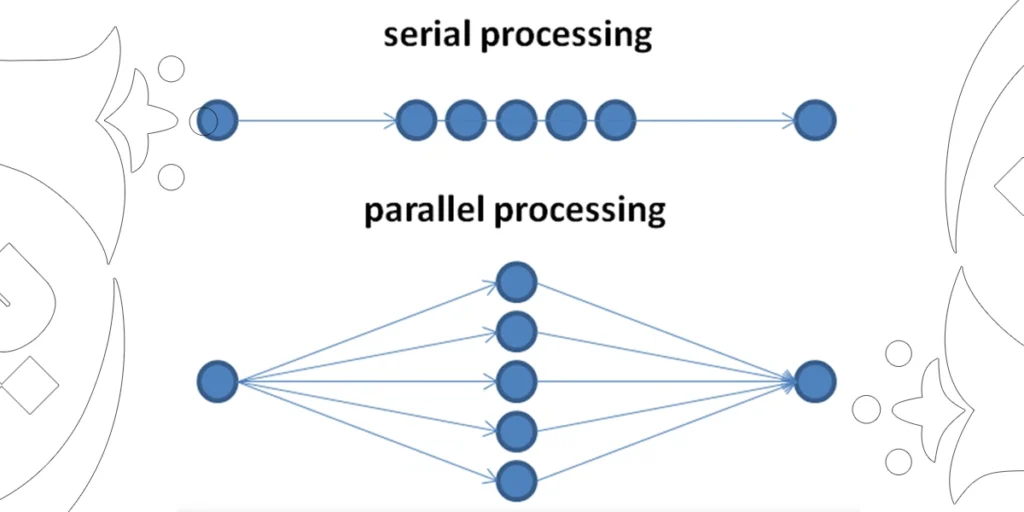
۳. تفاوت در سبک پردازش: ترتیبی در برابر موازی
Serial vs parallel
پردازش ترتیبی در CPU:
پردازندههای مرکزی برای اجرای دستورات بهصورت توالییافته (Serial) بهینه شدهاند. این رویکرد برای وظایف پیچیدهی منطقی، شرطی، و وابسته به جریان کنترل برنامه مناسب است. در بسیاری از کاربردهای عمومی سیستمعامل یا پردازشهای تراکنشی در دیتابیسها، CPU بهترین گزینه است.
پردازش موازی در GPU:
GPUها برای اجرای هزاران دستور ساده بهصورت همزمان (Parallel) طراحی شدهاند. این سبک پردازش بهطور خاص در الگوریتمهای یادگیری عمیق، شبکههای عصبی، رمزگذاری و رمزگشایی، شبیهسازیهای فیزیکی و گرافیک بسیار مؤثر است. به همین دلیل در سرورهایی مانند HPE ProLiant DL380 Gen10 Plus که از کارتهای NVIDIA پشتیبانی میکنند، GPU به یک ابزار ضروری برای پردازشهای هوش مصنوعی تبدیل شده است.

۴. نقش این تفاوتها در انتخاب سختافزار سرور
در انتخاب سختافزار برای دیتاسنتر یا پروژههای پردازشی، باید سبک و نیازمندی پردازش مشخص شود:
-
برای وظایف محاسباتی ترتیبی، کنترل منطقی، و پردازشهای تراکنشی → سرورهای مجهز به CPU با قدرت پردازش بالا (مانند HPE DL360 Gen10)
-
برای آموزش مدلهای هوش مصنوعی، تحلیل دادههای حجیم و شبیهسازی علمی → سرورهای مجهز به GPU پرقدرت مانند NVIDIA A100 یا H100 با پشتیبانی از معماری CUDA
مزایای GPU در پردازشهای سنگین: چرا GPU انتخاب اول در پروژههای HPC و AI است؟
در پروژههای پردازشی سطح بالا مانند یادگیری ماشین، شبیهسازی علمی، تحلیل دادههای عظیم و رندر گرافیکی، سرعت و کارایی در اجرای میلیاردها محاسبه عددی در زمان کوتاه، یک نیاز کلیدی است. در چنین شرایطی، پردازندههای گرافیکی (GPU) به دلیل معماری خاص خود، مزایای بیرقیبی نسبت به CPU دارند.
در ادامه، مهمترین دلایلی که باعث شده GPU در پردازشهای سنگین و پیشرفته برتری داشته باشد را بررسی میکنیم:
۱. توانایی پردازش موازی (Massive Parallelism)
یکی از اصلیترین مزایای GPU، ساختار مبتنی بر هزاران هسته موازی است. برخلاف CPU که معمولاً شامل تعداد محدودی هسته پیچیده و قدرتمند است، GPU از صدها تا هزاران هسته ساده بهره میبرد که قادر به پردازش همزمان حجم عظیمی از دادهها هستند.
مزایای پردازش موازی در عمل:
-
پردازش میلیونها پیکسل در رندرینگ گرافیکی
-
آموزش مدلهای هوش مصنوعی در زمان کوتاهتر
-
اجرای سریع الگوریتمهای پیچیده علمی و آماری
در سرورهای پیشرفتهای نظیر HPE ProLiant DL380 Gen10 Plus که از کارتهای NVIDIA A100 و H100 پشتیبانی میکنند، این توانایی پردازش موازی، زمان اجرای پروژههای یادگیری عمیق را از روزها به چند ساعت کاهش میدهد.
۲. بهرهوری بالا در پردازش ماتریسی و برداری
بخش بزرگی از الگوریتمهای یادگیری ماشین و شبیهسازیهای علمی بر پایه محاسبات ماتریسی و برداری استوار هستند. معماری GPU بهطور خاص برای چنین پردازشهایی طراحی شده است. واحدهای اختصاصی مانند Tensor Core در کارتهای مدرن NVIDIA برای شتابدهی به عملیات ماتریسی طراحی شدهاند.
کاربردهای پردازش ماتریسی:
-
ضرب و تقسیم ماتریسها در شبکههای عصبی
-
انجام عملیات برداری سنگین در مدلهای فیزیکی
-
شتابدهی به تحلیل دادههای چندبعدی در علوم داده
در مقایسه با CPU، یک GPU قدرتمند میتواند عملیات ماتریسی را دهها برابر سریعتر انجام دهد، آن هم با مصرف انرژی کمتر و بهینهتر.
۳. توان محاسباتی در مقیاس بالا (High Throughput Computing)
توان محاسباتی GPUها بر اساس معیار FLOPS (Floating Point Operations per Second) سنجیده میشود. در این زمینه، GPUهای دیتاسنتری مانند NVIDIA A100 و H100 توانایی ارائه چندین PetaFLOPS در محاسبات FP16 و FP32 دارند.
| پردازنده | حداکثر توان محاسباتی | نوع عملیات |
|---|---|---|
| Intel Xeon Scalable (مثلاً 8380) | ~3.5 TFLOPS | FP64 |
| NVIDIA A100 (80GB) | ~19.5 TFLOPS | FP32 |
| NVIDIA H100 (80GB) | ~60 TFLOPS | FP32 |
| NVIDIA H100 (Tensor Core) | تا 1 PFLOPS | FP8/INT8 |
این اعداد بیانگر آن هستند که در پروژههای با حجم پردازش بالا (مانند یادگیری عمیق، شبیهسازی ژنتیکی یا تحلیل مالی)، GPU میتواند جایگزینی ایدهآل برای CPU یا مکملی توانمند در کنار آن باشد.
۴. مصرف انرژی بهینه در ازای توان خروجی بالا
در سرورهای HPE که برای استفاده از GPU طراحی شدهاند (نظیر HPE Apollo 6500 Gen10 Plus یا HPE ProLiant XL675d Gen11)، معماری خنکسازی و تغذیه برق به گونهای طراحی شده که استفاده بهینه از انرژی در عین ارائه حداکثر توان محاسباتی تضمین شود. در نتیجه، کاربران سازمانی میتوانند با حداقل هزینه مصرف برق و خنکسازی، حداکثر بهرهوری پردازشی را به دست آورند.
۵. مقیاسپذیری بالا در محیطهای سازمانی
GPUها در معماریهای چندگانه (Multi-GPU) قابل گسترش هستند. بسیاری از سرورهای پیشرفته HPE قابلیت نصب ۴ تا ۸ عدد کارت GPU را بهصورت همزمان دارند که این ویژگی، قدرت پردازشی سرور را به سطح ابرکامپیوترها میرساند.
چرا GPU برای سازمانها ضروری شده است؟
در عصر انفجار داده و رشد سریع فناوریهای هوش مصنوعی، GPU به ابزاری حیاتی در زیرساختهای پردازشی تبدیل شده است. هر سازمانی که در حوزههایی مانند:
-
آموزش مدلهای یادگیری عمیق
-
اجرای پروژههای HPC و شبیهسازی
-
تحلیل حجیم دادههای مالی یا زیستی
فعال است، ناگزیر به تجهیز سرورهای خود به GPUهای قدرتمند خواهد بود.
در شبکه گستران یاقوت سرخ، ما راهکارهای حرفهای مبتنی بر سرورهای HPE سازگار با پردازندههای گرافیکی را با گارانتی و پشتیبانی تخصصی ارائه میدهیم. جهت دریافت مشاوره، میتوانید با کارشناسان ما تماس بگیرید.

GPU in AI
GPU در کاربردهای هوش مصنوعی و یادگیری ماشین (AI & Machine Learning)
با رشد شتابدار فناوریهای مبتنی بر هوش مصنوعی (AI) و یادگیری ماشین (ML)، نیاز به زیرساخت پردازشی توانمند بیش از هر زمان دیگر احساس میشود. در این میان، واحد پردازش گرافیکی (GPU) با ساختار موازی و قابلیتهای شتابدهی عددی، به مهمترین عنصر در معماری سیستمهای مبتنی بر AI تبدیل شده است.
سرورهای قدرتمند سری HPE ProLiant و Apollo که به صورت پیشفرض یا سفارشی از کارتهای گرافیک حرفهای مانند NVIDIA A100، H100 و L40S پشتیبانی میکنند، بستری مطمئن برای استقرار پروژههای یادگیری ماشین در سطح سازمانی و پژوهشی فراهم میکنند.
۱. آموزش مدلهای یادگیری عمیق (Deep Learning Training)
آموزش مدلهای یادگیری عمیق بهویژه شبکههای عصبی کانولوشنی (CNN) و بازگشتی (RNN) نیازمند انجام میلیاردها ضرب و جمع ماتریسی است. در این مرحله، GPU با توان بالای محاسبات برداری و پردازش همزمان هزاران هسته CUDA، به طرز چشمگیری سرعت آموزش را افزایش میدهد.
مزایای استفاده از GPU در آموزش مدل:
-
کاهش زمان آموزش مدلهای سنگین از چند روز به چند ساعت
-
امکان آموزش همزمان چند مدل با استفاده از چند GPU (Multi-GPU Training)
-
بهرهبرداری از FP16 و Tensor Core برای شتابدهی دقیق و بهینه
در سرورهایی مانند HPE Apollo 6500 Gen10 Plus، قابلیت پشتیبانی از چند GPU با پهنایباند بالا (NVLink) امکان آموزش مدلهای بسیار بزرگ مانند GPT، BERT یا Vision Transformer را فراهم میکند.
۲. تسریع در استنتاج مدلها (Inference Acceleration)
پس از آموزش، مدلها باید برای تحلیل دادههای جدید (مانند پردازش تصویر، زبان یا صوت) استفاده شوند. مرحله استنتاج یا Inference به تأخیر پایین (Low Latency) و مصرف انرژی بهینه نیاز دارد. GPU با طراحی خاص برای پردازش ماتریسی و پشتیبانی از فرمتهای سبکتر مانند INT8 و FP8 در کارتهایی مانند NVIDIA H100، انتخاب اول در پروژههای real-time است.
مزیت GPU در استنتاج مدل:
-
زمان پاسخ سریعتر در اپلیکیشنهای real-time (مانند خودروهای خودران یا سیستمهای توصیهگر)
-
پشتیبانی از هزاران درخواست بهصورت همزمان
-
قابلیت بهینهسازی مدل با TensorRT برای inference سریع و کممصرف

NVIDIA CUDA
۳. نقش CUDA و کتابخانههای تخصصی در تسریع AI
یکی از دلایل اصلی موفقیت GPU در پردازشهای AI، زیستبوم نرمافزاری غنی و بهینهشده توسط NVIDIA است. برنامهنویسان میتوانند با استفاده از زبان CUDA، مستقیماً به هستههای GPU دسترسی پیدا کنند. همچنین کتابخانههای تخصصی بسیاری برای آموزش و استنتاج مدلهای یادگیری عمیق بهینهسازی شدهاند.
مهمترین ابزارها و کتابخانهها:
| ابزار | توضیح |
|---|---|
| CUDA | زبان برنامهنویسی برای توسعه موازی بر بستر GPU |
| cuDNN | کتابخانهی تخصصی برای شبکههای عصبی عمیق |
| TensorRT | موتور inference بهینهسازیشده برای latency پایین |
| NCCL | برای ارتباط بین چند GPU در محیط چندگانه (Multi-GPU Communication) |
این ابزارها امکان بهرهبرداری حداکثری از توان GPU را فراهم کرده و کارایی نرمافزارهای محبوبی مانند TensorFlow، PyTorch، MXNet و ONNX Runtime را به طرز چشمگیری افزایش میدهند.
چرا سازمانها برای AI به GPU نیاز دارند؟
امروزه از تشخیص چهره و تحلیل تصاویر پزشکی تا پردازش زبان طبیعی و پیشبینی مالی، همگی بر پایه مدلهای یادگیری عمیق بنا شدهاند. بدون استفاده از GPU و زیرساخت مجهز به سرورهای HPE با پشتیبانی از چند GPU، اجرای این پروژهها در مقیاس واقعی ممکن نیست.
شبکه گستران یاقوت سرخ با ارائهی مشاوره، تأمین و پشتیبانی سرورهای تخصصی HPE GPU-Optimized، بستری مطمئن برای توسعه و پیادهسازی سامانههای هوش مصنوعی در ایران فراهم کرده است.
موارد استفادهی واقعی از GPU در هوش مصنوعی (Case Studies)
با افزایش توان پردازشی کارتهای گرافیک و پشتیبانی سرورهای مدرن مانند HPE ProLiant و HPE Apollo از GPUهای پیشرفته، بسیاری از پروژههای کلان هوش مصنوعی و تحلیل دادههای عظیم توانستهاند به مرحلهی اجرا برسند. در این بخش، چند نمونه واقعی از کاربرد موفق GPU در صنایع مختلف بررسی میشود.
۱. پروژههای هوش مصنوعی در مقیاس کلان
GPT، BERT و مدلهای زبانی بزرگ (LLM)
مدلهای زبانی مانند GPT-4 و BERT برای پردازش زبان طبیعی (NLP) نیاز به آموزش روی صدها میلیارد پارامتر دارند. این فرایند تنها با استفاده از هزاران کارت گرافیک NVIDIA A100 یا H100 به کمک تکنیکهایی مانند مدل پارالل و دیتا پارالل امکانپذیر شده است.
نکته کلیدی:
پلتفرمهایی مانند Microsoft Azure و Google Cloud از سرورهای چند-GPU و معماریهای مبتنی بر HPE و NVIDIA برای آموزش این مدلها بهره میبرند. شتابدهندههای NVIDIA با قابلیت NVLink و NVSwitch در سرورهای HPE Apollo 6500 Gen10 Plus، انتخاب اصلی برای اجرای مدلهای LLM در مقیاس ابری هستند.
AlphaGo و پروژههای یادگیری تقویتی (Reinforcement Learning)
پروژه مشهور AlphaGo توسط DeepMind، از صدها GPU برای اجرای همزمان بازیها، پردازش بردها و بهینهسازی مدل استفاده میکرد. بدون توان پردازشی موازی GPU، پیادهسازی یادگیری تقویتی با عمق زیاد (Deep RL) در عمل ممکن نبود.
۲. GPU در دیتاسنترها و سوپرکامپیوترها
GPU نهتنها در آموزش مدلها، بلکه در استنتاج real-time، پردازش دادههای علمی، و شبیهسازیهای پیچیده نیز در دیتاسنترها کاربرد دارد.
نقش GPU در دیتاسنترهای مدرن
امروزه ارائهدهندگان سرویسهای ابری مانند AWS، Azure و Google Cloud از GPUهای پیشرفته در زیرساختهای خود بهره میبرند. سرورهایی با طراحی ماژولار مانند HPE Cray XD و HPE Apollo توانایی استقرار تا ۸ یا ۱۰ GPU با پهنای باند بالا را در یک یونیت دارند.
ویژگیهای کلیدی GPU در دیتاسنتر:
-
کاهش بار پردازشی از روی CPUها
-
بهبود بهرهوری انرژی (Performance/Watt)
-
تسریع استنتاج برای هزاران درخواست همزمان (مثلاً در موتورهای جستجو یا شبکههای اجتماعی)

Summit supercomputer
GPU در سوپرکامپیوترها
سوپرکامپیوترهایی مانند Fugaku (ژاپن) و Summit (آمریکا) از ترکیب پردازندههای قدرتمند و GPU برای رسیدن به ترافلاپس بالا در محاسبات علمی، هواشناسی، مدلسازی کوانتومی و ژنتیک استفاده میکنند.
در پروژههای تحقیقاتی دانشگاهی یا هستهای، سرورهای GPU-محور مبتنی بر HPE با معماری خنکسازی ویژه و پشتیبانی از NVIDIA InfiniBand، نقش مهمی ایفا میکنند.
۳. استفاده از GPU در صنایع مختلف
الف. صنعت خودرو: خودروهای خودران
شرکتهایی مانند Tesla، Waymo و NVIDIA DRIVE از GPU برای پردازش real-time دادههای تصویری، لیدار، رادار و اجرای الگوریتمهای تصمیمگیری استفاده میکنند. هر خودروی خودران نیاز به پردازش چندین گیگابایت داده در ثانیه دارد و تنها GPUهای قدرتمند میتوانند این نیاز را برآورده کنند.
ب. پزشکی و بیوانفورماتیک
در تصویربرداری پزشکی (MRI، CT Scan) و تشخیص بیماریها با کمک هوش مصنوعی، GPUها نقش حیاتی دارند. به عنوان مثال:
-
شناسایی ناهنجاریهای ریوی از طریق CNN
-
تحلیل دادههای ژنوم با سرعت بالا
-
آموزش مدلهای تشخیص سرطان از تصاویر پاتولوژی
ج. خدمات مالی و فینتک (FinTech)
در صنعت مالی، GPU برای تحلیل رفتار کاربران، شناسایی تقلب (Fraud Detection)، پیشبینی بازار و اجرای الگوریتمهای معاملاتی سریع (HFT) کاربرد دارد. کارتهای GPU در سرورهای HPE امکان اجرای هزاران مدل تحلیلی را در لحظه فراهم میکنند.
کاربردهای GPU دیگر محدود به پردازشهای گرافیکی یا بازیهای کامپیوتری نیست. امروزه، GPU به عنوان یک شتابدهنده محاسباتی در قلب پروژههای هوش مصنوعی، یادگیری ماشین، تحلیل داده، و شبیهسازیهای پیچیده قرار گرفته است. سازمانهایی که بهدنبال تسریع پروژههای AI و افزایش توان رقابتی خود هستند، با سرمایهگذاری روی سرورهای مجهز به GPU از برند HPE میتوانند زیرساختی پایدار، مقیاسپذیر و قابل اطمینان ایجاد کنند.
شبکه گستران یاقوت سرخ، با تجربهی تخصصی در تأمین، پیکربندی و پشتیبانی سرورهای HPE، آمادهی ارائهی مشاوره در زمینه راهاندازی پلتفرمهای هوش مصنوعی در سطح سازمانی است.
محدودیتها و چالشهای GPU در کاربردهای سازمانی و دیتاسنترها
با وجود مزایای چشمگیر GPU در شتابدهی به پردازشهای هوش مصنوعی، یادگیری عمیق و تحلیل داده، استفاده از این واحدهای پردازشی در مقیاس سازمانی و درون دیتاسنترها با چالشها و محدودیتهایی همراه است که شناخت دقیق آنها برای طراحی زیرساخت بهینه بسیار ضروری است.
در ادامه به بررسی مهمترین چالشهای فنی و اقتصادی مرتبط با استفاده از GPU در سرورهای مدرن مانند HPE ProLiant و HPE Apollo میپردازیم.
۱. هزینه بالای تهیه و پیادهسازی GPU
قیمت سختافزار
GPUهای سازمانی مانند NVIDIA A100، H100، L40 و سایر کارتهای دیتاسنتری، هزینههای بسیار بالاتری نسبت به CPUها دارند. این هزینه نهتنها مربوط به خود کارت گرافیک، بلکه شامل اجزای جانبی مانند پاورهای ویژه، سیستم خنککننده، مادربردهای سازگار و سرورهای GPU-Ready نیز میشود.
هزینههای جانبی
-
هزینههای لایسنس نرمافزارهای CUDA یا ابزارهای مدیریت NVIDIA
-
نیاز به نیروی فنی متخصص برای پیکربندی و نگهداری
-
پیچیدگی در بهروزرسانی سیستمعاملها و درایورها برای پشتیبانی GPU
نکته تخصصی:
برندهایی مانند HPE، راهکارهایی ماژولار مانند HPE Apollo 6500 Gen10 Plus را با پشتیبانی تا ۸ GPU در یک شاسی ارائه میدهند که اگرچه هزینهبر است، اما در مقابل بهرهوری بالایی را برای پروژههای مقیاسپذیر فراهم میکند.
۲. مصرف انرژی بالا و چالشهای خنکسازی
توان مصرفی بالا
هر GPU قدرتمند مانند A100 ممکن است بین ۳۰۰ تا ۷۰۰ وات توان مصرفی داشته باشد. در صورت استفاده همزمان از چند کارت، مصرف برق کل سرور بهشدت افزایش مییابد که نیازمند ارتقاء زیرساخت برقرسانی و UPS خواهد بود.
نیاز به خنکسازی پیشرفته
حرارت تولید شده توسط GPUها، بهویژه در سناریوهای آموزش مدلهای بزرگ، بسیار بالاست. استفاده از سیستمهای خنکسازی سنتی در این شرایط ممکن است ناکارآمد باشد. دیتاسنترهایی که از سرورهای GPU محور استفاده میکنند اغلب به سیستمهای خنککنندهی مایع (Liquid Cooling) یا جریان هوای کانالدار (Ducted Airflow) نیاز دارند.
نکته فنی:
برخی مدلهای پیشرفتهی سرور HPE مانند HPE Cray XD2000 از معماری خنکسازی ترکیبی برای کنترل دمای GPU در حجم بار پردازشی سنگین بهره میبرند.
۳. وابستگی به CPU برای مدیریت منابع و اجرای Thread
مدل پردازشی ناهمگون (Heterogeneous Computing)
GPUها بهتنهایی قادر به اجرای مستقل سیستمعامل یا مدیریت حافظه و I/O نیستند. آنها نیاز دارند که یک پردازندهی مرکزی (CPU) عملیات مدیریت، زمانبندی تسکها و تخصیص منابع را انجام دهد. این وابستگی بهویژه در سرورهای multi-GPU و دیتاسنترهای مجازیسازیشده میتواند منجر به گلوگاه (Bottleneck) شود.
مشکلات مربوط به هماهنگی CPU-GPU
-
تاخیر در ارسال و دریافت داده بین CPU و GPU از طریق PCIe
-
وابستگی به کیفیت درایورها برای عملکرد پایدار
-
تفاوت در معماری حافظه که مدیریت Shared Memory را دشوار میکند
راهکار پیشنهادی:
سرورهایی با پشتیبانی از PCIe Gen4/Gen5 و پردازندههای جدید HPE با معماری AMD EPYC یا Intel Xeon Scalable میتوانند تأخیرهای ارتباطی را کاهش دهند و کارایی GPU را افزایش دهند.
هرچند استفاده از GPU در سرورهای سازمانی و پروژههای هوش مصنوعی یک ضرورت روبهرشد است، اما تصمیمگیری در خصوص پیادهسازی آن باید با درنظر گرفتن چالشهایی همچون هزینه بالا، مصرف انرژی زیاد، وابستگی ساختاری به CPU و نیاز به زیرساخت پیشرفته خنکسازی و تغذیه برق انجام گیرد. شرکتهایی که در مراحل ابتدایی ورود به حوزه GPU و پردازش موازی هستند، لازم است از مشاوره تخصصی بهرهمند شوند.
شبکه گستران یاقوت سرخ با تخصص در تأمین، طراحی و پشتیبانی سرورهای HPE مجهز به GPU، آماده ارائهی مشاوره فنی برای انتخاب بهینهترین راهکار براساس نیاز هر سازمان است.
آیندهی معماریهای پردازشی در دیتاسنترها و سرورهای سازمانی
رشد پرشتاب دادهها، پیشرفتهای چشمگیر در حوزه یادگیری ماشین، و نیاز روزافزون به قدرت محاسباتی در سازمانها، باعث تغییرات بنیادی در معماریهای پردازشی شده است. در آیندهی نزدیک، دیگر خبری از تکیهی مطلق بر CPU نخواهد بود؛ بلکه معماریهای هیبریدی، ترکیبی از انواع واحدهای پردازشی را برای دستیابی به حداکثر کارایی به کار خواهند گرفت.
۱. ظهور معماریهای هیبریدی (CPU+GPU، TPU، FPGA)
در معماریهای سنتی، CPU بهعنوان مغز پردازشی سیستم مسئول اجرای همهی تسکها بود، اما امروزه شاهد تولد ساختارهایی هستیم که وظایف تخصصی را میان انواع مختلف پردازندهها تقسیم میکنند.
CPU+GPU: مدل غالب در زیرساختهای مدرن
در اکثر سرورهای پیشرفته مانند HPE Apollo 6500 Gen10 Plus، ترکیب CPUهای قدرتمند (Intel Xeon یا AMD EPYC) با GPUهای شتابدهنده مانند NVIDIA A100 بهعنوان استاندارد غالب معماری پذیرفته شده است. این مدل هیبریدی مزایای زیر را دارد:
-
افزایش چشمگیر توان پردازشی در پردازشهای موازی و یادگیری ماشین
-
تقسیم بهینهی وظایف: مدیریت منابع توسط CPU و اجرای موازی توسط GPU
-
مقیاسپذیری برای نیازهای پیشرفتهی مدلسازی، تحلیل داده و بینایی ماشین
TPU (Tensor Processing Unit)
پردازندههای اختصاصی گوگل برای اجرای مدلهای یادگیری عمیق با چارچوب TensorFlow طراحی شدهاند. اگرچه استفاده از TPU در سطح کلان بیشتر در زیرساختهای ابری مانند Google Cloud رواج دارد، اما احتمال توسعه سرورهای On-Premise مجهز به TPU در سالهای آینده وجود دارد.
FPGA (Field Programmable Gate Arrays)
FPGAها پردازندههای قابل برنامهریزی برای اجرای وظایف خاص مانند رمزنگاری، پردازش ویدئو یا تسریع شبکه هستند. برند HPE نیز در سرورهایی مانند HPE ProLiant DL380 Gen10 Plus امکان استفاده از کارتهای FPGA را فراهم کرده است تا مشتریان سازمانی بتوانند تسکهای خاص را با تأخیر پایینتر و بهرهوری بالاتر انجام دهند.
بیشتر بخوانید: معرفی iLO7 بر روی سرورهای HPE Gen12
۲. جایگاه CPU در اکوسیستم آینده
با وجود همهی تحولات، CPU همچنان نقش حیاتی خود را حفظ خواهد کرد. زیرا:
-
همچنان برای اجرای سیستمعامل، مدیریت حافظه، I/O و فرآیندهای ترتیبی ضروری است
-
اغلب بارهای کاری عمومی (General Purpose Workloads) به CPU نیاز دارند
-
در بسیاری از کاربردهای Virtualization و مدیریت منابع، CPU تنها گزینهی پایدار و سازگار است
شرکت HPE نیز با ادامهی همکاری خود با Intel و AMD، همواره در حال ارائه نسلهای جدیدی از سرورها با CPUهای بهینه شده برای ترکیب با GPU و FPGA است.
۳. بررسی روند توسعه GPUها (NVIDIA، AMD، Intel)

intel amd nvidia gpu card
NVIDIA
NVIDIA با معرفی معماریهای Ampere، Hopper و در آینده Blackwell، مسیر توسعه GPU را بهسمت هوش مصنوعی و پردازش ابری سوق داده است. خانوادههای A100، H100 و L40S اکنون قلب بسیاری از سرورهای HPC و AI را تشکیل میدهند. شتابدهندههای NVIDIA علاوه بر قدرت خام بالا، با ابزارهایی مانند NVIDIA CUDA Toolkit و NVIDIA AI Enterprise اکوسیستم گستردهای برای توسعه فراهم کردهاند.
AMD
AMD نیز با معماری CDNA در حال رقابت جدی با NVIDIA است. کارتهای سری MI200 و MI300 مخصوص مراکز داده طراحی شدهاند و با بهرهگیری از HBM (حافظه با پهنای باند بالا)، عملکرد چشمگیری در محیطهای HPC و یادگیری عمیق از خود نشان دادهاند.
Intel
Intel با GPUهای سری Ponte Vecchio و Max Series در حال ورود جدی به بازار دیتاسنتری است. این شرکت همچنین ترکیب معماری x86 با شتابدهندههای گرافیکی و ادغام پردازنده و GPU در یک چیپ (Integrated Heterogeneous Compute) را دنبال میکند.
آیندهی معماریهای پردازشی بدون تردید ترکیبی و تخصصی خواهد بود. سازمانهایی که در پی پیادهسازی زیرساختهای پردازشی پایدار، مقیاسپذیر و متناسب با نیازهای AI و تحلیل داده هستند، باید از همین امروز بهدنبال معماریهای هیبریدی و راهکارهای مدرن باشند. برند HPE با ارائهی سرورهایی انعطافپذیر، قابل توسعه و کاملاً سازگار با فناوریهای روز مانند GPU، FPGA و Smart NICها، یکی از پیشگامان این تحول محسوب میشود.
شرکت شبکه گستران یاقوت سرخ بهعنوان مرجع تخصصی تأمین و پشتیبانی سرورهای HPE در ایران، آماده ارائهی مشاوره، طراحی زیرساخت و فروش تجهیزات پردازشی پیشرفته برای سازمانها، شرکتهای فناوری، مراکز داده و پژوهشگاههاست.
جمعبندی و نتیجهگیری
معماری x86 طی چند دهه گذشته بهعنوان استاندارد غالب در دنیای سرورها و دیتاسنترها شناخته شده و نقش کلیدی در توسعه زیرساختهای فناوری اطلاعات ایفا کرده است. در این مقاله، با بررسی دقیق ویژگیها، مزایا، محدودیتها و روندهای نوظهور در حوزه معماریهای پردازشی، تلاش شد تا تصویری شفاف و کاربردی از وضعیت فعلی و آینده این معماری در صنعت سرور ترسیم شود.
مرور مزایا و معایب معماری x86
مزایا:
-
سازگاری گسترده: پشتیبانی از انواع سیستمعاملها، hypervisorها، نرمافزارها و ابزارهای سازمانی
-
انعطافپذیری بالا: مناسب برای طیف متنوعی از بارهای کاری، از سرورهای عمومی تا محاسبات سنگین
-
جامعه توسعهدهنده و پشتیبانی قدرتمند: منابع آموزشی، نرمافزار و فریمورکهای توسعهیافته برای x86 در دسترس است
-
قابلیت ادغام با فناوریهای نوین: مانند GPU، FPGA، Smart NIC و معماریهای هیبریدی
معایب:
-
مصرف انرژی نسبتاً بالا در مقایسه با معماریهایی مانند ARM، بهویژه در مقیاس دیتاسنتری
-
طراحی پیچیدهتر و محدودیت در بهینهسازی مصرف انرژی برای بارهای خاص
-
چالش در رقابت با معماریهای نوظهور در حوزههای خاص مانند یادگیری ماشین یا IoT

CPU or GPU
پاسخ نهایی به پرسش اصلی مقاله
اگر بخواهیم بهصورت شفاف به سؤال اصلی این مقاله پاسخ دهیم که «آیا معماری x86 همچنان برای سرورها بهترین انتخاب است؟»، باید گفت:
بله، معماری x86 همچنان ستون فقرات اصلی زیرساختهای سروری سازمانی در جهان است و برای بسیاری از سناریوها، از جمله مجازیسازی، تحلیل داده، پردازش ابری و اجرای بارهای کاری عمومی، گزینهای بسیار قدرتمند، پایدار و قابل اعتماد محسوب میشود. با این حال، برای بارهای کاری خاص (مانند AI، HPC، Edge Computing) معماریهای ترکیبی یا جایگزین نیز میتوانند گزینههایی بهینه باشند.
پیشنهادهایی برای ادامه تحقیق یا پروژههای عملی
۱. مقایسه عملی عملکرد CPUهای x86 با معماریهای ARM در سرورهای نسل جدید HPE
۲. تحلیل اقتصادی TCO (Total Cost of Ownership) سرورهای مبتنی بر x86 در مقابل سایر معماریها در محیطهای واقعی دیتاسنتری
۳. طراحی سناریوهای هیبریدی با استفاده از CPUهای x86 در کنار GPUهای NVIDIA/AMD در سرورهای HPE Apollo و ProLiant
۴. پایش گرایشهای آینده بازار با تمرکز بر کاربرد پردازندههای ARM در دیتاسنترهای hyperscale
۵. بررسی تأثیر x86 در تطبیقپذیری سازمانها با نیازهای تحول دیجیتال (Digital Transformation)
شبکه گستران یاقوت سرخ با برخورداری از تیم متخصص، تجربهی گسترده در پیادهسازی زیرساختهای سازمانی، و نمایندگی رسمی فروش و پشتیبانی سرورهای HPE در ایران، آماده ارائه مشاوره تخصصی، طراحی معماری و تأمین تجهیزات مبتنی بر جدیدترین نسل از پردازندههای x86 است. برای دریافت راهنمایی بیشتر، میتوانید با کارشناسان فنی ما تماس بگیرید یا درخواست خود را از طریق وبسایت ثبت نمایید.
































