



مجازی سازی و کاربردهای آن
فناوریهای مجازی سازی از دهه 1960 وجود داشته است. با شروع پروژههای اطلس(Atlas) و M44/44X ، مفهوم تقسیم زمان و حافظه مجازی به دنیای رایانه معرفی شد. بودجهای که توسط مراکز تحقیقاتی بزرگ و تولیدکنندگان سیستم تأمین میشد، بنابراین فناوری مجازی سازی اولیه فقط در اختیار کسانی بود که منابع کافی و نفوذ کافی برای تأمین هزینه خرید تجهیزات آهن آلات بزرگ را داشتند.
با تکامل تقسیم زمان، IBM ریشهها و معماری اولیه مانیتور ماشین مجازی یا VMM را توسعه داد. بسیاری از ویژگیها و عناصر طراحی System370 و تکرارهای موفقیت آمیز آن هنوز در فناوریهای مجازی سازی مدرن یافت میشود. پس از یک دوره کوتاه سکوت هنگامی که دنیای محاسبات چشم از مجازی سازی گرفت، تأکید دوبارهای در اواسط دهه 1990 آغاز شد و مجازی سازی را دوباره در کانون توجهات خود قرار داد تا به عنوان وسیلهای موثر برای کسب بازده بالا از سرمایه گذاری یک شرکت باشد. در سال 1998، VMware تاسیس شد و شروع به ارائه نرمافزاری برای مجازی سازی دسکتاپ و همچنین سرورها کرد.
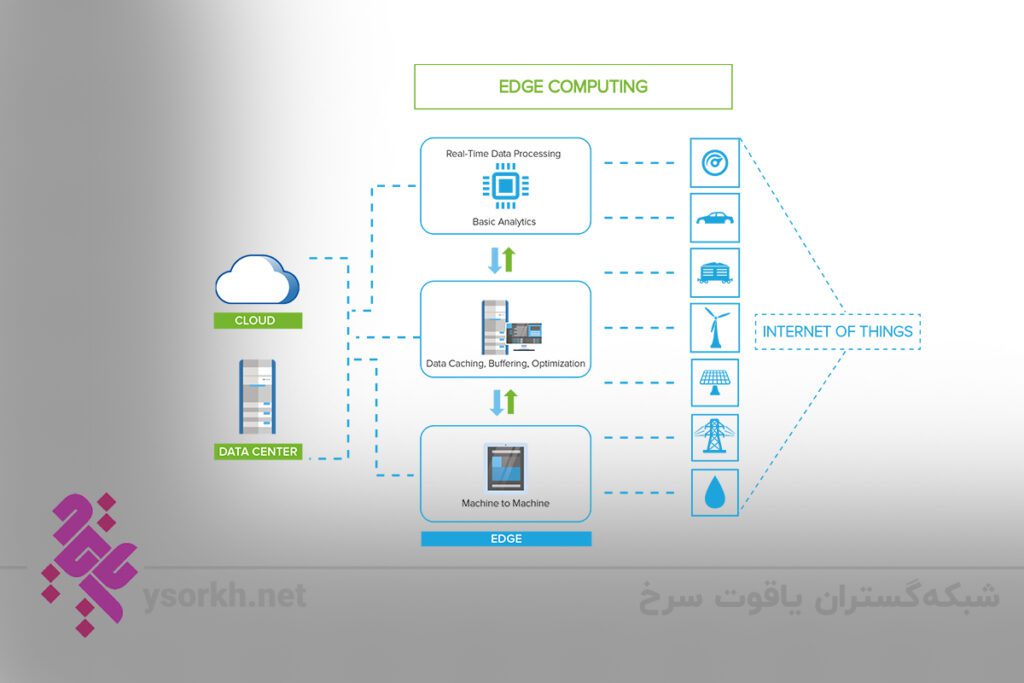
محیطهای مجازی
فناوری مجازی سازی یک رویکرد فنی جایگزین را برای ارائه زیرساختها، سیستمعاملها و پلتفرمها، سرورها، نرم افزارها و سیستمها و برنامهها فراهم میکند. اکثر محیطهای محاسباتی مجازی اشتراکات زیادی با مراکز داده معمولی دارند، اما از سخت افزار و نرم افزار تخصصی با عملکرد بالا استفاده میکنند که یک سرور فیزیکی را قادر میسازد به عنوان چندین نمونه همزمان اجرا شود. این رویکرد باعث افزایش استفاده از ظرفیت میشود و در مدلهای مبتنی بر خدمات فناوری اطلاعات مانند رایانش ابری، به سازمانها این امکان را میدهد تا با کوچک کردن یا پایین آمدن نیازهای تجاری، از منابع IT خود استفاده بهینه کنند. ممیزی محیطهای محاسباتی مجازی از بسیاری از روشها و معیارهای مشابه برای ممیزیهای مرکز داده استفاده میکند، با تأکید بیشتر بر تهیه، از بین بردن، مدیریت و نگهداری چندین سرور مجازی که منابع محاسباتی، شبکهای و زیرساختی را به اشتراک میگذارند.
استفاده از رایانش ابری و ارائهدهندگان خدمات شخص ثالث مرتبط به اندازه کافی رایج شده است که ممکن است حسابرسیهای فناوری اطلاعات چنین خدمات متمایزی از سایر مولفههای حسابرسی شده را بررسی کنند. از بسیاری جنبهها، از جمله استفاده قابل توجه از فناوری مجازی سازی، خدمات رایانش ابری کاملاً مشابه میزبانی برنامههای متداول برنامه برون سپاری و خدمات زیرساخت مدیریت شده است که مدتها توسط برخی سازمانها استفاده میشده است. تمایزاتی که توسط فروشندگان خدمات ابری مورد تأکید قرار میگیرد ، شامل ارائه خدمات درخواستی، دسترسی همه جا به شبکه، تجمیع منابع، قابلیتها و خدمات انعطافپذیر و استفاده از اندازهگیری و مدلهای مربوط به قبض و پرداخت است. رشد پیش بینی شده در محاسبات ابری یکی از عوامل ایجاد انگیزه در توسعه چارچوبهای کنترل ابری خاص است، به ویژه برای رفع نگرانیها در مورد امنیت اطلاعات در محاسبات ابری. چارچوبهای موجود شامل ماتریس کنترلهای ابری است که توسط اتحادیه غیرانتفاعی Cloud Security Alliance و برنامه مدیریت ریسک و مجوز فدرال (FedRAMP) اداره شده توسط اداره خدمات عمومی جهت استفاده توسط ارائه دهندگان خدمات ابری که به سازمان های دولتی ایالات متحده خدمت میکنند، تهیه شده است. این چارچوبهای کنترل به مراجعان فناوری اطلاعات، نقاط مرجع دیگری در مورد انواع کنترلهایی که باید در محیطهای رایانش ابری وجود داشته باشند، ارائه میدهند.
تحلیل جرمشناسی(forensic)
فناوری مجازی سازی مزایای بسیاری در زمینه digital forensics دارد. با مجازی سازی، محققان توانایی تولید forensics با کیفیت بالاتر را در مدت زمان کمتری دارند. انتخاب refresh تصویر برای اطمینان از یکپارچگی دیگر دردناک نیست. این یک لمس ساده از دکمه refresh است. انتقال از ابزارهای ویندوز به ابزارهای Unix فقط یک راه اندازی مجدد است. مجازی سازی به ما امکان میدهد کامپیوتر مظنون را که بدون ترس از آلودگی بر روی دادههای مظنون کار میکند، مشاهده کنیم. این به تنهایی استفاده از مجازی سازی را مطلوب میکند، اما موارد بسیار بیشتری وجود دارد. مجازی سازی به ما توانایی تجزیه و تحلیل تلههای انفجاری و بمبهای ساعتی را که فرد مظنون بر جای گذاشته است، بدون به خطر انداختن شواهد میدهد. اگر پروندهای که شما در حال بررسی آن هستید بر کل شرکت شما تأثیر میگذارد، مجازی سازی به شما امکان میدهد رایانه مشکوک را برای جمع آوری اطلاعات درباره مولفههای خارجی حادثه و شناسایی مشارکت کنندگان داخلی مشاهده کنید.
ترکیب مجازی سازی سرور و استوریج
با ترکیب مجازی سازی سرور با مجازی سازی استوریج، میتوان مجموعه دیسک و حجم مجازی ایجاد کرد که با توجه به نیاز برنامهها، ظرفیت آنها را میتوان در صورت تقاضا افزایش داد. بازده معمول ذخیره سازی آرایههای ذخیره سازی سنتی در محدوده 30-40٪ است. مجازی سازی استوریج میتواند با توجه به گزارشهای خاص، بهرهوری را به 70٪ یا بیشتر برساند، که منجر به ذخیره سازی کمتر و صرفه جویی در انرژی میشود.

طبقه بندی مجازی سازی استوریجها
- مجازی سازی در سطح بلوک: این روش شامل ایجاد یک ذخیرهگاه با منابع از چندین دستگاه شبکه و در دسترس قرار دادن آنها به عنوان یک منبع ذخیره سازی مرکزی است. این روش که در بسیاری از SAN ها استفاده میشود ، مدیریت را ساده و هزینه را کاهش میدهد.
- مجازی سازی ردیف(tier) استوریج: این روش مجازی سازی معمولاً به عنوان مدیریت ذخیره سازی سلسله مراتبی (HSM) نامیده میشود و اجازه میدهد دادهها به طور خودکار بین انواع مختلف ذخیره سازی بدون نیاز به آگاهی کاربران منتقل شوند. سیستمهای نرمافزاری برای طبقه بندی خودکار برای انجام چنین فعالیتهای انتقال داده استفاده میشود. این روش هزینه و مصرف برق را کاهش میدهد زیرا اجازه میدهد فقط دادههایی که به طور مکرر دسترسی دارند در ذخیره سازی با کارایی بالا ذخیره شوند، در حالی که دادههایی که کمتر دسترسی دارند میتوانند در تجهیزات کمهزینه و کممصرف قرار بگیرند مانند MAID و تکثیر دادهها.
- مجازی سازی در طول زمان برای ایجاد آرشیو فعال: این نوع مجازی سازی استوریج، که به عنوان آرشیو فعال نیز شناخته میشود، مفهوم مجازی سازی را گسترش میدهد و دسترسی آنلاین به دادههایی را که در غیر اینصورت آفلاین هستند امکان پذیر میکند. از سیستمهای نرمافزاری مجازی سازی ردیف برای شناسایی پویا دادههایی که باید در کتابخانههای پشتیبان گیری از دیسک به دیسک یا کتابخانههای نوار آرشیو شوند و یا به حافظه ذخیره سازی فعال برگردانده شوند، استفاده می شود.
مدل سازی تخصیص VM
با فناوریهای مجازی سازی، رایانش ابری انعطاف پذیری در تخصیص منابع را فراهم میکند. به عنوان مثال، PM با دو هسته پردازشی میتواند همزمان یا در هر هسته میزبان دو یا چند ماشین مجازی باشد. ماشینهای مجازی فقط درصورتی تخصیص مییابند که کل مقدار پردازش استفاده شده توسط همه ماشینهای مجازی موجود در یک میزبان بیشتر از مقدار موجود در آن هاست نباشد.
با استفاده از مثال پرکاربرد Amazon EC2 ، نشان میدهیم که امکان نمایش یکنواخت انواع مختلف ماشین مجازی وجود دارد. Amazon EC2 اطلاعاتی در مورد پیکربندی سخت افزار خود ارائه نمیدهد. با این حال، بر اساس واحدهای محاسبه میتوانیم سه نوع PM مختلف (یا pools PM) مختلف تشکیل دهیم. برای مثال، در یک CDC واقعی می توان PM با حافظه 2 × 68.4 گیگابایت، 16 هسته × 3.25 واحد و 2 × 1690 GB حافظه ذخیره سازی ارائه داد. به این ترتیب، یک نمای یکنواخت از انواع مختلف ماشین مجازی احتمالاً شکل میگیرد. این نوع طبقه بندی دید واحدی از منابع مجازی شده برای پلتفرمهای ناهمگن مجازی سازی، مثل Xen، KVM ، VMWare فراهم میکند و مزایای زیادی برای مدیریت و تخصیص VM به همراه دارد. مشتریان فقط بر اساس نیاز خود نیاز به انتخاب انواع مناسب ماشین مجازی دارند.
در حال حاضر، الگوریتمهای تعادل بار پویا CloudSched ، حداکثر استفاده و الگوریتمهای زمان بندی با صرفه جویی در انرژی را پیاده سازی میکند. الگوریتمهای دیگری مانند قابلیت اطمینانگرا و هزینهگرا نیز میتوانند اعمال شوند.
آینده فناوری مجازی سازی
فناوری مجازی سازی تأثیر بسزایی در صنعت IT خصوصاً در مراکز داده برای صرفهجویی در هزینهها و افزایش عملکرد دارد. در سمت پنهان کردن دادهها، ماشین مجازی میتواند از داخل درایو zip USB استفاده و راه اندازی شود. این خطرات بزرگی را متوجه سازمانهایی میکند که سعی در مبارزه با نشت دادهها دارند. کاربر میتواند به طور کامل از طریق درگاه USB سیستمعامل خود را راه اندازی کند، به وی اجازه میدهد تا از ابزار steganography استفاده کند بدون اینکه اثری از دستگاه میزبان باقی بگذارد. اگر دسترسی به USB توسط سیاست امنیتی سازمان ممنوع باشد (و این یک اقدام امنیتی عالی است که باید بدون استثنا اجرا شود) ، کاربر میتواند از مدل محاسبات ابری IaaS استفاده کند و نرم افزار VM را روی حساب میزبان نصب کند. سپس او می تواند اقدامات stego را در سرور راه دور انجام دهد، بنابراین تمام اقدامات امنیتی شبکه مربوط به مبارزه با تکنیکهای پنهان کردن دادهها را دور میزند.
ماشین مجازی همچنین میتواند یک چالش واقعی را برای محققان forensic تحمیل کند. یک کاربر میتواند یک فعالیت مجرمانه انجام دهد یا دادهها را با استفاده از VM پنهان کند و سپس آنها را از دستگاه میزبان پاک کند. بازیابی پروندههای VM حذف شده (به ویژه پس از پاک کردن داده ها بر روی HDD) و بازیابی اطلاعات از آن در بسیاری از شرایط بسیار دشوار و غیرممکن است.
به طور خلاصه، برای افزایش امنیت در یک سازمان، اقدامات منظمی که توسط کاربران عادی انجام میشود باید محدود شود. به عنوان مثال، بهتر است دسترسی به همه مدلهای خدمات ابری را ممنوع کرده و از نظر فنی از اتصال USB و همه دستگاههای قابل جابجایی کاربران به شبکه شرکتی جلوگیری کنید. همچنین توصیه میشود از همگام سازی کاربران تلفن همراه با رایانههای شخصی و استفاده از اتصالات اینترنتی شرکتی در دستگاههای تلفن همراه خود جلوگیری کنید.
فناوری مجازی سازی به سرعت در حال پیشرفت است، در حالی که توسعه دهندگان بیشتر قصد دارند برنامههای سازگار با ابر را ایجاد کنند. همه این پیشرفتها را می توان بعداً جستجو کرد تا تکنیکهای پنهان سازی داده ها و نشت دادهها را ساده کند.
محاسبه و مجازی سازی استوریج
با استفاده از فناوری مجازی سازی محاسبات تا زمان رواج مراکز داده گسترش نیافت و نیاز به ایجاد و خراب کردن سرورها و همچنین انتقال آنها از یک سرور فیزیکی به سرور دیگر، اهمیت پیدا کرد. با وجود این، وضعیت عملیات مرکز داده بلافاصله تغییر کرد. سرورها می توانند با یک کلیک ماوس نمونه برداری شوند و بدون اینکه مختل عملکرد سرور در حال حرکت باشد، جابجا شوند.
ایجاد یک ماشین مجازی جدید یا انتقال یک ماشین مجازی از یک سرور فیزیکی به سرور دیگر، از دید مدیر سرور ساده است و ممکن است خیلی سریع انجام شود. نرم افزار مجازی سازی، مانند VMware ، Hyper-V ، KVM و XenServer نمونه هایی از محصولاتی است که به مدیران سرور اجازه میدهد تا به راحتی ماشینهای مجازی را ایجاد و جابجا کنند. این زمان مورد نیاز برای راه اندازی یک نمونه جدید از سرور را به چند دقیقه یا حتی چند ثانیه کاهش داده است.
به همین ترتیب، مجازی سازی استوریج برای مدتی وجود داشته است، همانطور که مفهوم انتزاع بلوکهای ذخیره سازی و اجازه جدا شدن آنها از سختافزار واقعی ذخیره سازی فیزیکی وجود دارد. همانند سرورها، این امر از نظر سرعت (به عنوان مثال ، انتقال داده های اغلب استفاده شده به دستگاه سریعتر) و همچنین از نظر استفاده (به عنوان مثال ، اجازه دادن به چندین سرور برای به اشتراک گذاشتن یک دستگاه ذخیره سازی فیزیکی) به بازدهی می رسد.
این پیشرفت های تکنولوژیکی باعث می شود تا سرورها و ذخیره سازی سریع و کارآمد دستکاری شوند. در حالی که این پیشرفتها در مجازی سازی رایانه و استوریج در حال انجام بوده است، اما در دامنه شبکه صدق نکرده است.
بهرهوری انرژی در مراکز داده و ابرها:
افزایش Hypervisor
فناوری مجازی سازی تأثیر امیدوارکنندهای در استفاده از منابع در مراکز داده دارد. از آنجایی که نگرانی اصلی در زمان طراحی ناظران کنونی مانند Xen ، برنامههای پرمحاسبهای است که آنها از عملکرد ضعیف ورودی و خروجی شبکه رنج میبرند. به عنوان مثال، مجازی سازی I/O تک ریشه، که استاندارد فعلی مجازی سازی شبکه است، براساس وقفه است. از آنجا که مدیریت هر وقفه هزینه بر است، عملکرد مجازی سازی شبکه بستگی به سیاست تخصیص منابع در هر hypervisor دارد.
برای غلبه بر مشکل فوق، مکانیزم جمع آوری بستهای را پیشنهاد میشود که میتواند فرآیند انتقال را به روشی کارآمدتر و سریعتر اداره کند. با این حال، مرحله جمع آوری خود منبع جدیدی از تأخیر را معرفی میکند و باید به آن پرداخته شود. از این رو، تئوری صف بندی برای مدل سازی و تنظیم پویا سیستم به منظور دستیابی به بهترین معامله بین تأخیر و توان استفاده شده است.
در مورد مشکل سیاست تخصیص منابع، برنامه ریز مبتنی بر اعتبار، برنامه ریز منابع واقعی در Xen hypervisor ، نمی تواند از پس کارهای فشرده I/O به درستی برآید. دلیل این امر این است که از رفتارهای مختلف ماشینهای مجازی مختلف آگاهی ندارد و همه آنها را به یک شکل اداره میکند. بنابراین، ماشینهای مجازی با شدت I/O اعتبار کافی برای مدیریت وقفههای شبکه را ندارند و بنابراین دادهها را به صورت آهسته بازیابی میکنند که منجر به تأخیر زیاد و زمان پاسخ میشود.
برای مقابله با مشکل ذکر شده و از بین بردن گلوگاهی(bottleneck) که ناشی از زمانبند است، یک مدل مجازی سازی شبکه با حجم کار را معرفی میشود. این مدل رفتار VM ها را کنترل میکند و آنها را بر اساس رفتار آنها در دو دسته I/O-intensive و CPU زیاد تقسیم میکند و سپس آنها را با برنامه ریزی مشترک و تخصیص اعتبار Agile کنترل میکند. هنگامی که یک ماشین مجازی با شدت ورودی و خروج با انفجار ترافیک روبرو میشود، برنامه ریزی مشترک اعتبار بیشتری به آن میدهد تا بتواند از پس ترافیک برآید. تخصیص اعتبار چابک وظیفه تنظیم اعتبار کل را بر اساس تعداد ماشین های مجازی با شدت I/O جهت کاهش زمان انتظار برای هر یک از ماشین های مجازی با شدت I/O بر عهده دارد.
روش دیگر، ابتدا یک شکاف معنایی را ایجاد میشود که بین VMM و VM وجود دارد. شکاف این است که VMM از فرایندهای داخل VM ها بیاطلاع است بنابراین نمیتواند زمانبندی VM ها را به طور مثر انجام دهد. به عنوان مثال، هنگامی که یک VM به یک VM مستقر دیگر می فرستد، VM مستقر باید vCPU کسب کند تا بتواند درخواست را پردازش کند و پاسخ را ASAP ارائه دهد اما برنامه ریزی فعلی در VMM این موضوع را در نظر نمیگیرد. در نتیجه، تأخیر پاسخ افزایش مییابد و ممکن است منجر به نقض کیفیت خدمات (QoS) شود. علاوه بر این، هنگامی که ماشین های مجازی مستقر در CPU یا IO فشرده باشند، بدتر میشود زیرا رقابت برای CPU به طور چشمگیری افزایش مییابد. برای حل این مشکل، الگوریتم زمان بندی بین VM (CIVSched) آگاه از ارتباطات را ارائه میشود که از ارتباط بین ماشینهای مجازی مستقر آگاه است. CIVSched بستههایی را که از طریق شبکه ارسال میشوند، رصد میکند و VM مورد نظر را شناسایی میکند و VM را به گونهای برنامه ریزی میکند که تاخیر پاسخ را کاهش دهد. نمونه اولیه CIVSched در Xen hypervisor پیاده سازی شده است.
برای هر مهمان DomU (VM) ، یک درایور جلویی مجازی وجود دارد که VM درخواستهای عملیات I/O را برای آن ارسال میکند. سپس این درخواستها به درایور پشتی که در مهمان Dom0 است ارسال میشود. و سرانجام، درایور back-end درخواستهای گرفته شده را به درایور واقعی دستگاه می فرستد و پاسخها را به درایور front-end برمیگرداند.
CIVSched باید از دو اصل طراحی پیروی کند: تأخیر کم برای بین VM و تأخیر کم برای روند داخلی VM. این دو اصل طراحی به CIVSched کمک میکند تاخیر بین VM را کاهش دهد. برای تحقق بخشیدن به دو نیاز فوق، CIVSched پنج ماژول به مکانیسم I/O Xen اضافه میکند. ماژول AutoCover (کشف خودکار) ماشین های مجازی مستقر را پیدا میکند و آدرس MAC و شناسههای آنها را در یک جدول نقشه برداری ذخیره میکند. CivMonitor تمام بستههای منتقل شده توسط ماشینهای مجازی را بررسی میکند و هنگامی که یک بسته بین VM را پیدا میکند، CivScheduler را در این باره آگاه میکند. سپس، CivScheduler اعتبار بیشتری را برای هدف قرار دادن VM فراهم میکند تا بتواند بستهها را در سریعترین زمان ممکن اداره کند. تا به حال، اولین اصل طراحی (تأخیر کم برای inter-VM) برآورده شده است اما مورد دیگر هنوز هم نیاز به توجه دارد. با توجه به اصل دوم، CivMonitor فرایند هدف VM را شناسایی می کند که بسته را از طریق شماره پورت TCP / UDP درون بسته دریافت میکند و اطلاعات را به VM هدف منتقل میکند. سرانجام ، ماژول های PidScheduler و PidTrans در داخل VM مهمان فرایند هدف را با توجه به کاهش تاخیر زمان بندی میکنند.
برای ارزیابی CIVSched ، آن را در Xen hypervisor نسخه 4.1.2 پیاده سازی کردهاند و با زمانبند XenandCo (زمانبندی پیشنهادی دیگری برای Xen) و زمانبند اعتبار که زمانبندی پایه در Xen است مقایسه میشود. برای مقایسه تأخیر شبکه، آزمایشات شامل یک تست پینگ پنگ، یک آزمایش شبیه سازی و یک سناریوی برنامه وب واقعی اما با معیارهای ترکیبی است. ضمانتهای انصاف نیز ارزیابی میشود زیرا انصاف زمانبند مستقیماً بر انصاف منابع CPU اختصاص یافته به هر ماشین حساب تأثیر میگذارد. مجموعه UnixBench 4.1.0 برای ارزیابی عملکرد سربار CIVSched بر عملکرد میزبان به کار گرفته شده است. سربار عملکرد در دو سطح اندازهگیری میشود: هنگامی که فقط دو ماشین مجازی بر روی میزبان وجود دارد (تلفیق سبک) و وقتی هفت ماشین مجازی وجود دارد که به طور همزمان بر روی میزبان اجرا میشوند (تلفیق سنگین).

مجازی سازی داده ها
از فناوری مجازی سازی داده میتوان برای ایجاد بستر انبار داده نسل بعدی استفاده کرد. بزرگترین مزیت این استقرار استفاده مجدد از زیرساختهای موجود برای بخش ساختار یافته انبار داده است. این روش همچنین فرصتی را برای توزیع موثر حجم کار در سیستم عامل فراهم می کند و بدین ترتیب امکان بهینه سازی در معماریها فراهم می شود. مجازی سازی دادهها همراه با معماری معنایی قوی میتواند یک راهحل مقیاس پذیر ایجاد کند.
مزایا: معماری فوق العاده مقیاس پذیر و انعطاف پذیر، حجم کار بهینه شده، ساه بودن نگهداری و هزینه اولیه کمتر برای استقرار.
معایب: عدم حاکمیت میتواند سیلوها را بیش از حد ایجاد کند و عملکرد را کاهش دهد، پردازش جستجوی پیچیده میتواند در طی یک دوره زمانی تخریب شود، عملکرد در لایه ادغام ممکن است به نگهداری دورهای نیاز داشته باشد.
بارگذاری داده در سراسر لایهها جدا شده است. این یک پایه و اساس برای ایجاد یک استراتژی قوی مدیریت داده فراهم میکند.
در دسترس بودن دادهها برای هر لایه کنترل میشود و میتوان قوانین امنیتی را در صورت لزوم برای هر لایه پیاده سازی کرد، و از هرگونه هزینه اضافی مرتبط برای سایر لایهها جلوگیری می کند.
حجم داده ها را میتوان در لایههای جداگانه دادهها براساس نوع داده، نیازهای چرخه زندگی برای دادهها و هزینه ذخیره سازی مدیریت کرد.
عملکرد ذخیره سازی بر اساس دسته بندی دادهها و نیازهای عملکردی است و میتوان ردیفهای ذخیره سازی را پیکربندی کرد.
هزینه های عملیاتی، در این معماری محاسبه هزینه عملیاتی دارای اجزای ثابت و متغیر است. هزینه های متغیر مربوط به زیرساخت های پردازش و محاسبات و هزینههای نیروی کار است. هزینههای ثابت مربوط به نگهداری از بستر مجازی سازی دادهها و هزینههای مربوط به آن است.













