یکی از اجزای حیاتی در پایداری سرور، کنترلرهای RAID هستند که مدیریت ذخیرهسازی دادهها را به شکل امن و بهینه بر عهده دارند. در سرورهای HP، این کنترلرها اگرچه از پایداری بالایی برخوردارند، اما گاهی به دلایل سختافزاری یا نرمافزاری دچار خطا میشوند؛ خطاهایی که در صورت تشخیص نادرست یا واکنش دیرهنگام، ممکن است منجر به از دست رفتن اطلاعات یا توقف سرویسها شوند. در این مقاله از یاقوت سرخ، با نگاهی فنی و کاربردی به رایجترین خطاهای کنترلر RAID در سرور HP میپردازیم و راهکارهای عملی و تجربهمحور برای رفع آنها ارائه خواهیم داد. پس بهتر است قبل از خرید ریدکنترلر سرور و تعویض قطعه ابتدا این مقاله را تا انتها مطالعه کنید:
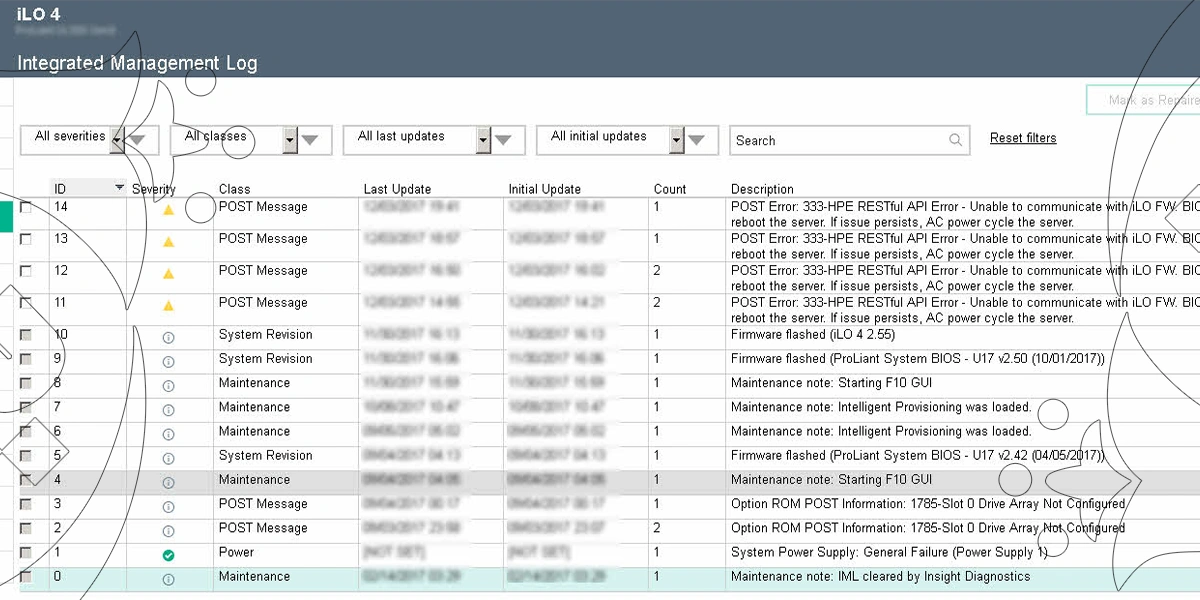
RAID Controller Error در سرور HP چیست؟ جدول ارورها
خطای «RAID Controller Error» در سرور HP به مشکلی گفته میشود که در آن کنترلر RAID—مرکز مدیریت آرایههای دیسک—در عملکرد خود دچار اختلال میشود. این اختلال ممکن است به دلایل مختلفی از جمله خرابی سختافزاری کنترلر، ناسازگاری درایورها، بهروزرسانی ناقص فریمور، یا حتی مشکلات محیطی مانند نوسانات برق و گرمای بیش از حد رخ دهد . نشانههای این خطا میتواند شامل پیامهای هشدار در هنگام بوت، عدم شناسایی دیسکها، عملکرد کند یا ناپایدار آرایههای RAID، و در برخی موارد از دست رفتن دادهها باشد. در ادامه، جدولی از خطاها و کدهای هشدار رایج در کنترلرهای RAID سرورهای HP ارائه شده است.. تشخیص بهموقع و رفع این خطاها برای حفظ پایداری و امنیت دادههای سازمانی حیاتی است.
| کد یا پیغام خطا | نوع ارور | توضیح فنی کاربردی |
|---|---|---|
1783 - Slot X Controller Failure |
خطای کنترلر در اسلات X | کنترلر شناسایی نشده یا به درستی در اسلات PCIe نصب نشده است. |
1785 - Drive Array Not Configured |
آرایه درایو پیکربندی نشده است | کنترلر هیچ آرایهای شناسایی نکرده. ممکن است پیکربندی از بین رفته یا تازه نصب شده باشد. |
1792 - Controller Failure |
خرابی کنترلر RAID | معمولا به دلیل خطای سختافزاری یا خرابی باتری کش اتفاق میافتد. |
Cache Module Battery Low |
باتری ماژول کش ضعیف است | باتری نیاز به شارژ دارد یا در حال پایان عمر مفید خود است. |
Logical Drive Degraded |
آرایه منطقی در وضعیت کاهشیافته (Degraded) | یک یا چند دیسک از آرایه خارج شدهاند؛ در صورت عدم واکنش، دادهها در معرض خطر هستند. |
Predictive Failure |
احتمال خرابی پیشبینیشده | کنترلر تشخیص داده که دیسک در آستانه خرابی است، بهتر است سریعاً جایگزین شود. |
Drive Rebuilding |
دیسک در حال بازسازی (Rebuild) | پس از تعویض یا اتصال مجدد دیسک، کنترلر در حال بازیابی دادهها است. |
Interim Recovery Mode |
حالت بازیابی موقت | کنترلر تلاش میکند دادهها را از منابع باقیمانده بازیابی کند؛ وضعیت بحرانی است. |
Write-Through Mode Active |
حالت Write-Through فعال است | کش درایو به دلیل خطا یا خرابی باتری غیرفعال شده؛ عملکرد سیستم کاهش مییابد. |
Event ID 11 – Disk |
خطای دیسک در سیستمعامل | معمولاً به دلیل تاخیر در پاسخگویی یا قطع ارتباط دیسکها با کنترلر ایجاد میشود. |
Event ID 129 – Reset to Device |
ریست شدن دیوایس توسط سیستمعامل | درایو یا کنترلر پاسخ نداده و سیستم آن را ریست کرده؛ احتمال خرابی فیزیکی وجود دارد. |
برای هر کد خطا، بهترین روش بررسی مشاهده جزئیات آن در محیطهای iLO، SSA یا Event Viewer ویندوز است. بهخصوص در محیطهایی با اهمیت بالا مانند سرورهای فایل، مجازیسازی یا دیتابیس، هرکدام از این پیغامها باید جدی گرفته شود.
✅ اگر در مورد کدی خاص یا پیام خاصی نیاز به تفسیر فنی دقیق دارید، کافیست آن را برای تیم فنی یاقوت سرخ ارسال کنید تا در سریعترین زمان تحلیل و راهکار مناسب ارائه شود.

گارانتی یاقوت سرخ
دلایل متداول خطا در ریدکنترلر سرور
خطا در کنترلرهای RAID میتواند به دلایل مختلفی اتفاق بیافتد، که شناسایی درست آنها نقش مهمی در پیشگیری از خرابیهای گستردهتر دارد.در ادامه به 6 دلیل عمده خطاهای RAID کنترلر می پردازیم:
-
خرابی سختافزاری کنترلر: مانند هر قطعه الکترونیکی دیگر، کنترلرهای RAID نیز ممکن است به مرور زمان دچار خرابی شوند. این خرابیها میتوانند منجر به از دست رفتن ارتباط با دیسکها یا عملکرد ناپایدار سیستم شوند.
-
بهروزرسانی ناقص یا قدیمی بودن فریمور: استفاده از فریمورهای قدیمی یا بهروزرسانی ناقص آنها میتواند باعث بروز ناسازگاریها و خطاهایی در عملکرد کنترلر شود. بهروزرسانی منظم فریمور کنترلر و درایورها میتواند بسیاری از این مشکلات را برطرف کند.
-
نصب نادرست یا ناسازگاری سختافزاری: نصب نادرست کنترلر یا استفاده از قطعات ناسازگار با مدل سرور میتواند منجر به بروز خطاهایی مانند “1783-Slot 0 Drive Array Controller Failure” شود. اطمینان از سازگاری قطعات و نصب صحیح آنها ضروری است.
-
نوسانات برق و مشکلات پاور: نوسانات برق یا استفاده از منابع تغذیه نامناسب میتواند به کنترلر آسیب رسانده و عملکرد آن را مختل کند. استفاده از منابع تغذیه پایدار و محافظتشده توصیه میشود.
-
گرمای بیش از حد و تهویه نامناسب: دمای بالا و تهویه نامناسب میتواند باعث افزایش دمای کنترلر و در نتیجه بروز خطا یا خرابی آن شود. اطمینان از عملکرد صحیح سیستمهای خنککننده و تهویه مناسب درون رکها اهمیت دارد.
-
خطاهای نرمافزاری و ناسازگاری با سیستمعامل: در برخی موارد، خطاهای نرمافزاری یا ناسازگاری بین کنترلر و سیستمعامل میتواند منجر به بروز مشکلاتی در عملکرد RAID شود. بهروزرسانی درایورها و استفاده از نسخههای سازگار سیستمعامل میتواند این مشکلات را کاهش دهد.
شناخت پیامهای خطا و کدهای هشدار RAID
درک درست از پیامهای خطا و کدهای هشدار کنترلر RAID، یک مهارت کلیدی برای هر مدیر شبکه است. بسیاری از خطاهای سطح RAID در صورت واکنش سریع، قابل کنترل و رفع هستند. اما در صورتی که این پیامها نادیده گرفته شوند، ممکن است به از دست رفتن داده یا توقف سرویسهای حیاتی منجر شود. این پیامها از طریق محیط POST هنگام راهاندازی سرور، ابزارهای مدیریتی مانند HPE Smart Storage Administrator (SSA)، iLO و نیز Event Viewer ویندوز قابل مشاهدهاند.
انواع رایج پیامهای هشدار و خطا
-
پیامهای بوت (POST Errors):
هنگام روشن شدن سرور، اگر مشکلی در شناسایی یا عملکرد کنترلر RAID وجود داشته باشد، پیامهایی مانند:-
1783-Slot X Drive Array Controller Failure -
1792-Controller Failure -
POST Error: 1785 - Drive Array Not Configured
مشاهده میشود. این خطاها اغلب نشاندهنده مشکلاتی در فریمور، پیکربندی یا خرابی سختافزاری کنترلر هستند.
-
-
وضعیت در ابزارهای مدیریتی (SSA و iLO):
این ابزارها پیامهایی مثل:-
Predictive Failure -
Drive Rebuilding -
Logical Drive Degraded
نمایش میدهند که بیانگر وضعیت سلامت دیسکها، آرایهها و کنترلر است. در این حالت کاربر میتواند به صورت گرافیکی وضعیت RAID را بررسی و اقدامات لازم را انجام دهد.
-
-
کدهای ثبتشده در سیستمعامل (Event Viewer در ویندوز):
کنترلر RAID معمولاً در صورت بروز خطا، پیامهایی مانند:-
Event ID 11 – Disk -
Event ID 129 – Reset to device
در لاگ ویندوز ثبت میکند. این خطاها عمدتاً مربوط به قطع ارتباط یا زمان پاسخدهی طولانی کنترلر هستند و نباید نادیده گرفته شوند.
-
بیشتر بخوانید: Power-On Self-Test چیست و آشنایی با انواع کدهای خطای POST در سرور
نحوه تفسیر و برخورد با خطاها
-
اول: تحلیل محیط بوت (POST):
اگر سرور هنگام روشن شدن خطا میدهد، باید از اتصال صحیح فیزیکی کنترلر، سلامت باتری کش، و سازگاری فریمور اطمینان حاصل کرد. -
دوم: بررسی وضعیت در SSA:
وارد محیط SSA شوید و سلامت هر Logical Drive، Physical Drive و Cache Module را بررسی کنید. هشدارهایی مانند “Rebuilding” یا “Interim Recovery Mode” نیاز به اقدام فوری دارند. -
سوم: مرور لاگ سیستم (Event Viewer):
اگر مشکلی در سطح سیستمعامل رخ دهد اما در POST یا SSA دیده نشود، احتمالاً با مشکلات نرمافزاری یا ناسازگاری درایور مواجه هستید. در این مرحله، بررسی بهروزرسانیها و درایورهای کنترلر پیشنهاد میشود.
روشهای عیبیابی اولیه خطاهای RAID در سرورهای HP
هنگامی که سرور شما پیغام خطا یا هشدار مرتبط با کنترلر RAID نمایش میدهد، مهمترین نکته واکنش سریع و اصولی برای جلوگیری از آسیب بیشتر به دادهها و عملکرد سرور است. در ادامه مراحل عیبیابی اولیه به ترتیب اولویت آورده شدهاند:
1. بررسی فیزیکی اولیه
-
وضعیت LED دیسکها را بررسی کنید. چراغهای نارنجی چشمکزن معمولاً نشاندهنده دیسک معیوب یا در حال Rebuild هستند.
-
اتصالات کابلهای SAS/SATA به کنترلر و درایوها را مجدداً بررسی و در صورت نیاز سفت کنید.
-
بررسی تهویه و دمای داخلی سرور (از طریق iLO یا محیط BIOS) برای اطمینان از عملکرد خنککننده.
HPE ilo Storage Information
2. مرور لاگها و پیغامهای سیستم
-
وارد محیط HPE iLO یا System Event Log (SEL) شوید و رخدادهای ثبتشده اخیر را مرور کنید.
-
اگر سیستم عامل ویندوز دارید، از Event Viewer بخش System و Application را برای پیامهای مرتبط با Disk، Storage Controller یا iLO بررسی نمایید.

HPE Smart Storage Administrator ( SSA )
3. بررسی از طریق HPE SSA
-
از طریق محیط HPE Smart Storage Administrator وارد شوید.
-
وضعیت آرایهها، Logical Drives، کش، و حالت کاری هر درایو را بررسی کنید.
-
اگر وضعیت Logical Drive روی حالت «Degraded» یا «Interim Recovery Mode» است، بدون تأخیر بکاپگیری را آغاز کنید.
بیشتر بخوانید: تشخیص و رفع خطاهای مادربرد سرورهای HP: ارور System Board
4. صحت پیکربندی RAID
-
مطمئن شوید که پیکربندی RAID بهدرستی انجام شده است.
-
در صورت وجود دیسک جدید، از تطابق نوع، سرعت و ظرفیت آن با آرایه اطمینان حاصل کنید.
5. بهروزرسانی فریمور و درایورها
-
از طریق HPE SUM یا iLO بررسی کنید که آیا فریمور کنترلر RAID بهروز است یا خیر.
-
درایورهای سیستمعامل مخصوص کنترلر (مانند درایور Smart Array) را با نسخههای موجود در سایت رسمی HPE تطبیق دهید.
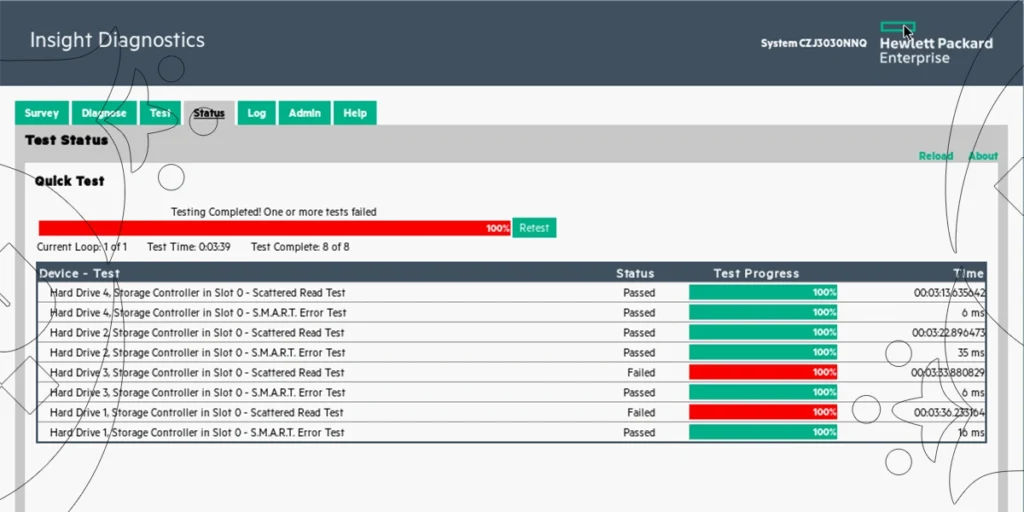
HPE Insight Diagnostic test
6. اجرای تست سلامت از طریق Diagnostics
-
در محیط Pre-boot، ابزار HP Insight Diagnostics را اجرا کرده و تست کامل روی کنترلر RAID و درایوها انجام دهید.
-
نتایج تست را بررسی و هرگونه پیام هشدار یا خطا را یادداشت کنید.
راهکارهای رفع خطاهای رایج کنترلر RAID در سرورهای HP
پس از شناسایی نوع خطا، نوبت به اجرای دقیقترین راهکار برای رفع آن میرسد. در این بخش، مجموعهای از راهحلهای عملی و مؤثر برای مهمترین خطاهایی که در محیطهای واقعی IT رخ میدهند، ارائه میشود.
1. خطای 1783 – Drive Array Controller Failure
این خطا معمولاً نشاندهنده خرابی سختافزاری کنترلر یا اتصال نادرست آن به مادربرد است.
✅ راهکار:
-
سرور را خاموش کرده و کنترلر RAID را از اسلات PCIe جدا و دوباره نصب کنید.
-
در صورتی که چند کنترلر دارید، با یک اسلات دیگر نیز تست کنید.
-
فریمور سرور و کنترلر را با استفاده از ابزار HPE SUM یا iLO بهروز نمایید.
-
اگر مشکل رفع نشد، کنترلر باید با نمونه سالم جایگزین شود.
2. Logical Drive Degraded
این وضعیت زمانی ایجاد میشود که یکی از درایوهای عضو RAID (معمولاً در RAID 1 یا RAID 5) دچار خرابی شده یا موقتاً از آرایه خارج شده است.
✅ راهکار:
-
وارد محیط HPE SSA شوید و دیسک معیوب را شناسایی کنید.
-
در صورت پشتیبانی از Hot-Plug، درایو را با دیسک سالم (با مشخصات کاملاً مشابه) تعویض و فرآیند Rebuild را مانیتور کنید.
-
در طول فرآیند Rebuild از انجام عملیات سنگین روی سرور اجتناب کنید.
3. Cache Module Battery Error
اگر باتری کش خراب یا خالی باشد، کنترلر در وضعیت Write-Through قرار میگیرد و عملکرد سیستم کاهش مییابد.
✅ راهکار:
-
از طریق SSA بررسی کنید که وضعیت کش روی Write-Back فعال است یا خیر.
-
در صورت مشاهده پیام خطای باتری، سرور را حداقل 24 ساعت روشن نگه دارید تا باتری شارژ شود.
-
اگر پس از شارژ همچنان خطا باقی است، باتری کش باید تعویض شود.
بیشتر بخوانید: راهنمای جامع رفع Cache Battery Failure و تاثیر آن بر رید کنترلر
4. RAID Not Configured – Error 1785
این خطا نشان میدهد که کنترلر RAID هیچ آرایهای را شناسایی نمیکند.
✅ راهکار:
-
وارد محیط SSA شوید و بررسی کنید آیا دیسکها توسط کنترلر شناسایی میشوند یا خیر.
-
اگر دیسکها دیده میشوند اما پیکربندی RAID از بین رفته، احتمال خرابی تنظیمات NVRAM وجود دارد. در این شرایط، استفاده از ابزار ACU یا SSA Recovery Mode ممکن است بتواند پیکربندی قبلی را بازیابی کند.
-
اگر هیچ دیسکی شناسایی نمیشود، کابلها، بکپلین یا کنترلر باید بررسی شوند.
5. پیغامهای مکرر Event ID 11 یا 129 در ویندوز
نشاندهنده ارتباط ناپایدار بین کنترلر و دیسکها است.
✅ راهکار:
-
درایورهای کنترلر را از وبسایت رسمی HPE دانلود و بهروزرسانی کنید.
-
بررسی کنید آیا نسخه BIOS و فریمور سرور نیز بهروز است.
-
در صورت ادامه خطاهای RAID کنترلر، امکان وجود مشکل در کابلکشی یا نویز الکترومغناطیسی وجود دارد.
چک لیست پیشگیری از خطاهای RAID کنترلر
پایداری RAID وابسته به اقدامات پیشگیرانه، نظارت هوشمندانه و نگهداری مداوم است. وقتی سرور شما در شرایط ایدهآل کار میکند، نباید منتظر بروز خطا بمانید. در عوض، با پیشبینی دقیق، میتوان بسیاری از اختلالات را از ابتدا حذف کرد. در ادامه به صورت چک لیست پیشگیری از خطاهای RAID کنترلر این موارد را در نظر داشته باشید:
1. بهروزرسانی منظم فریمور و درایورها
2. مانیتورینگ پیوسته با استفاده از ابزارهای HPE
3. بکاپگیری منظم
4. بررسی دورهای سلامت هارددیسکها
5. مدیریت دما و تهویه رک
6. مستندسازی و ثبت تغییرات
کلام آخر
در نهایت، شناخت دقیق کدهای هشدار و خطاهای RAID کنترلر در سرورهای HP و آشنایی با روشهای عیبیابی و رفع مشکلات، نقشی کلیدی در حفظ پایداری و امنیت دادهها دارد. اجرای اقدامات پیشگیرانه مانند بهروزرسانی منظم فریمور، مانیتورینگ مستمر سلامت سختافزار و تهیه نسخههای پشتیبان منظم، میتواند از بروز بسیاری از خطاهای رایج جلوگیری کند و در مواقع بروز مشکل، واکنش سریع و هدفمند را ممکن سازد. این را بدانید که هیچ RAIDی جایگزین بکاپ نیست. حتی RAID 10 نیز از خطاهای منطقی یا حذف اشتباه دادهها محافظت نمیکند. در این مسیر، تیم فنی یاقوت سرخ آماده است تا با ارائه مشاوره تخصصی و پشتیبانی حرفهای، همراه شما باشد.